Are Normalizing Flows
Good Candidates for
Interactive World Models?
Talk @ EDGE Workshop · Jun 3, 2026
Acting in the world needs a model of it

Choice 1 — react. Look at the image, directly predict which block to pull.
Choice 2 — simulate. Model the tower's state → predict the outcome of each pull → pick the move that keeps it standing.
Interactive decisions require rolling out the consequences of actions — i.e. a world model you can query.
Normalizing Flows in one slide
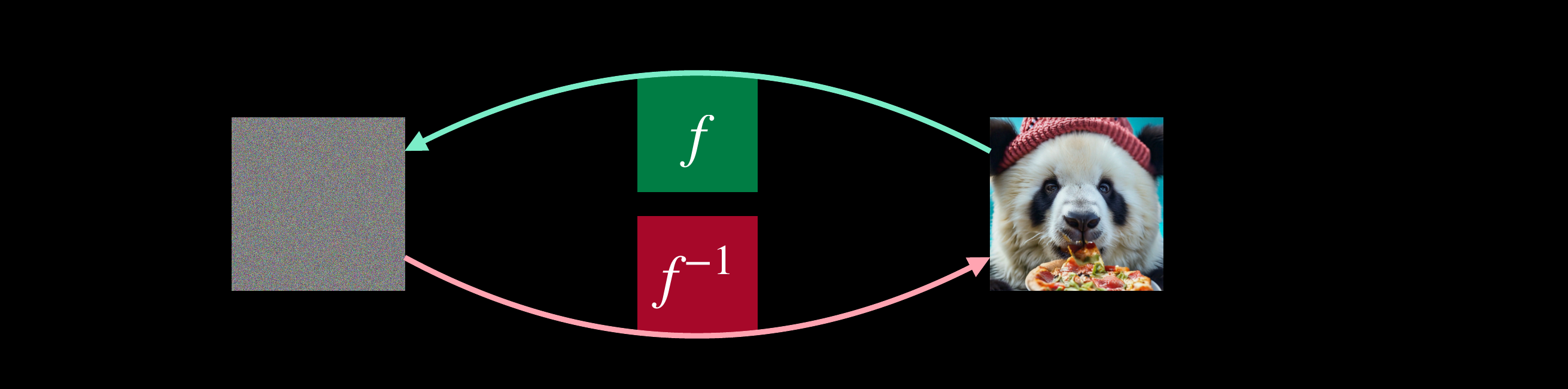
$p(x) = p_0\!\big(f(x)\big)\,\Big|\det \tfrac{\partial f(x)}{\partial x}\Big|,\qquad z=f(x)\ \text{invertible}$
Exact likelihood
trained by exact MLE — a single objective.
trained by exact MLE — a single objective.
Invertible
$x \leftrightarrow z$ is lossless — no information discarded.
$x \leftrightarrow z$ is lossless — no information discarded.
End-to-end
no noise schedule, no discretization.
no noise schedule, no discretization.
TARFlow — NFs are capable generative models
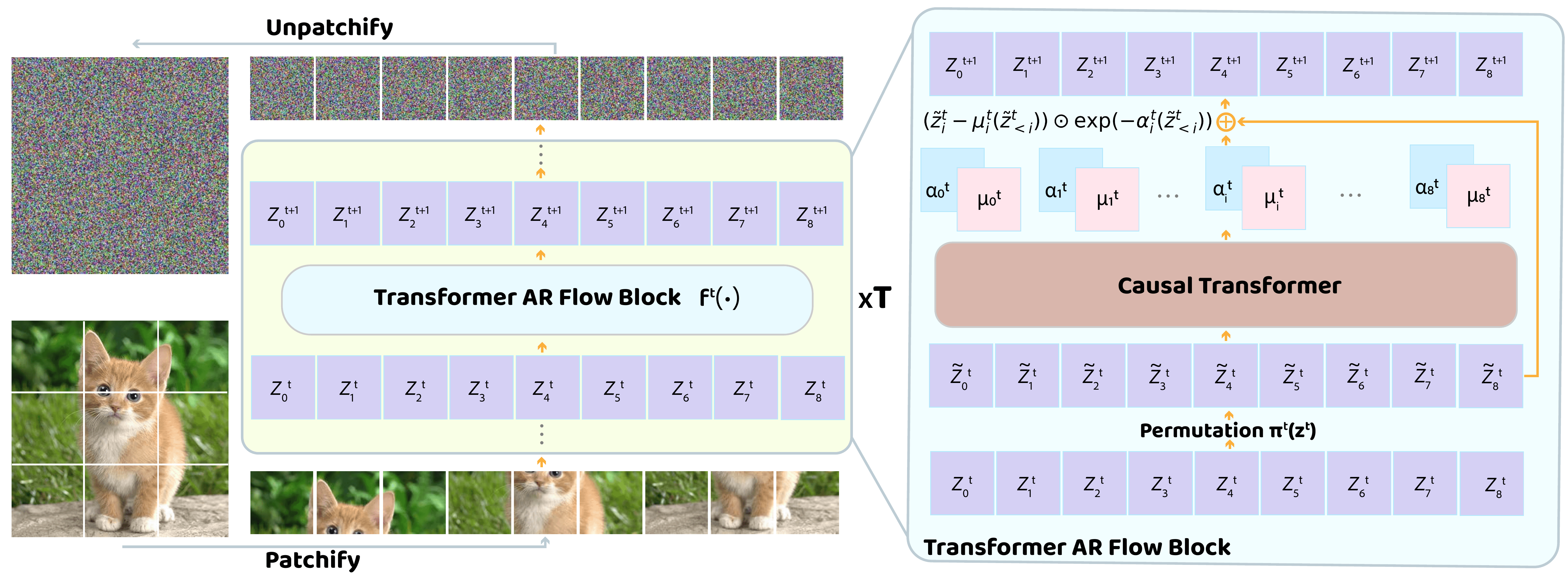
Transformer AR Flow. Stacked autoregressive Transformer blocks over patches, alternating scan direction.
Simple recipe — noise augmentation + post-hoc denoising + guidance → diffusion-level samples and SOTA likelihoods, from a stand-alone NF.
Normalizing Flows are Capable Generative ModelsS. Zhai, R. Zhang, P. Nakkiran, D. Berthelot, J. Gu, H. Zheng, T. Chen, M. Bautista, N. Jaitly, J. Susskind · ICML 2025 (Oral)
STARFlow — scaling latent NFs to high resolution

Deep–shallow design. One deep Transformer block carries most capacity + a few efficient shallow blocks.
Latent space. Model in a pretrained autoencoder's latent, not pixels — far more effective at high resolution.
+ new guidance, staying an end-to-end MLE flow. First NF at this scale/resolution, approaching diffusion quality.
STARFlow: Scaling Latent Normalizing Flows for High-resolution Image SynthesisJ. Gu, T. Chen, D. Berthelot, H. Zheng, Y. Wang, R. Zhang, L. Dinh, M. Bautista, J. Susskind, S. Zhai · NeurIPS 2025 (Spotlight)
Architecture: global–local
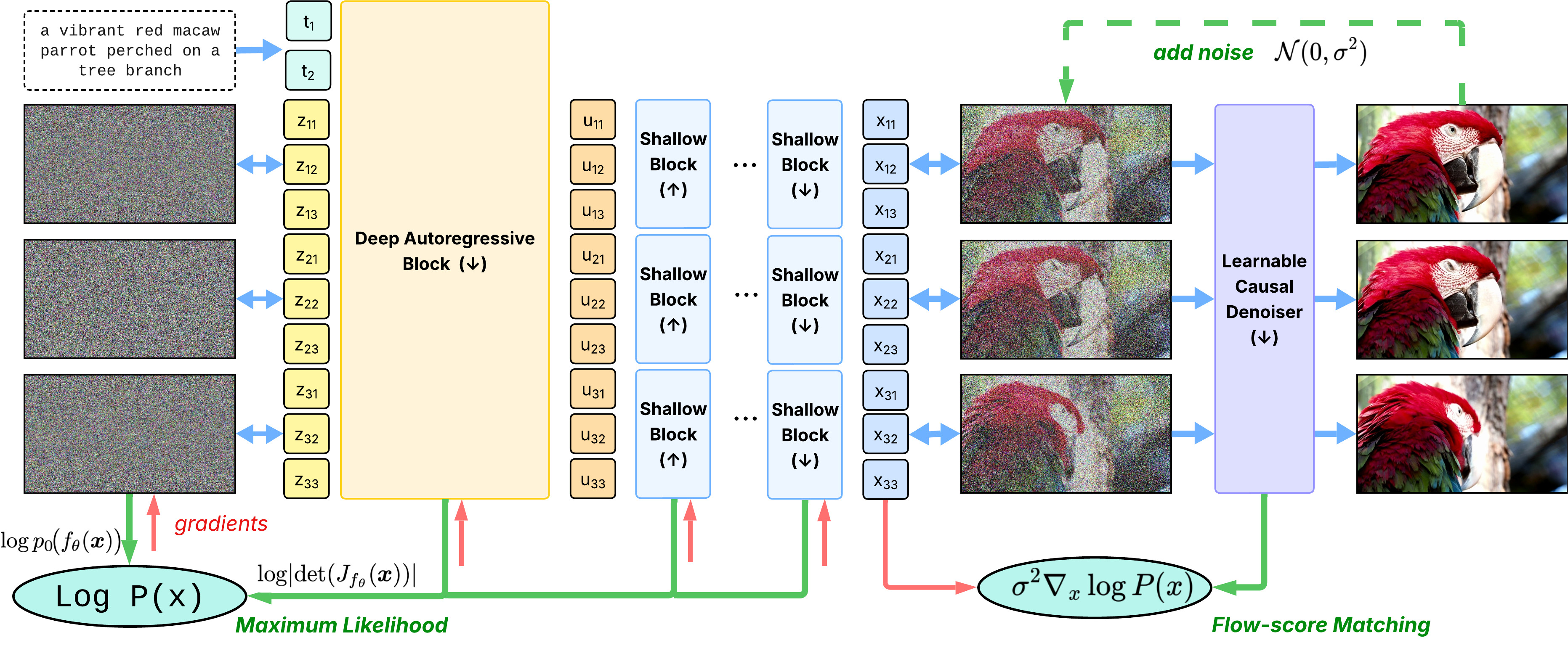
Deep AR block $f_D$ — causal Transformer carrying global long-range temporal context (left-to-right across frames). Causality lives here.
Shallow blocks $f_S$ — restricted within each frame, alternating masks → rich local interactions. $f_S^{-1}$ decodes frames independently.
STARFlow-V: End-to-End Video Generative Modeling with Normalizing FlowsJ. Gu, Y. Shen, T. Chen, L. Dinh, Y. Wang, M. Bautista, D. Berthelot, J. Susskind, S. Zhai · CVPR 2026 (Highlight)
NFM: inherit the coupling from an NF

Don't compute a coupling — read one off. A pretrained autoregressive NF already encodes a deterministic, per-sample, class-aware noise↔data bijection. Use its latent $z_{\epsilon'}=f_{\text{NF}}(x)/\sigma_f$ to replace the independent Gaussian noise; everything else in flow matching is unchanged.
The Coupling Within: Normalized Flow MatchingD. Berthelot, T. Chen, J. Gu, M. Cuturi, L. Dinh, B. Chandna, M. Klein, J. Susskind, S. Zhai · arXiv 2026
Can we do better? Enter NTM

NTM — text-to-image samples at 4 denoising steps (Fig 1)
Normalizing Trajectory Models (NTM) keep exact likelihood throughout — end-to-end, single training, and still sharp in as few as 4 steps.
The problem: Gaussian steps fail when coarse

Diffusion assumes each reverse step is a single small Gaussian. Compress to a few coarse steps and the true reverse $p(x_s\mid x_t)$ becomes a multimodal mixture — the Gaussian assumption breaks, so 4-step flow matching stays blurry.
Each step = an expressive conditional NF. The Gaussian assumption is replaced with a full NF transporter — model the true multimodal reverse exactly.
Normalizing Trajectory ModelsJ. Gu, T. Chen, Y. Shen, D. Berthelot, S. Zhai, J. Susskind · arXiv 2026
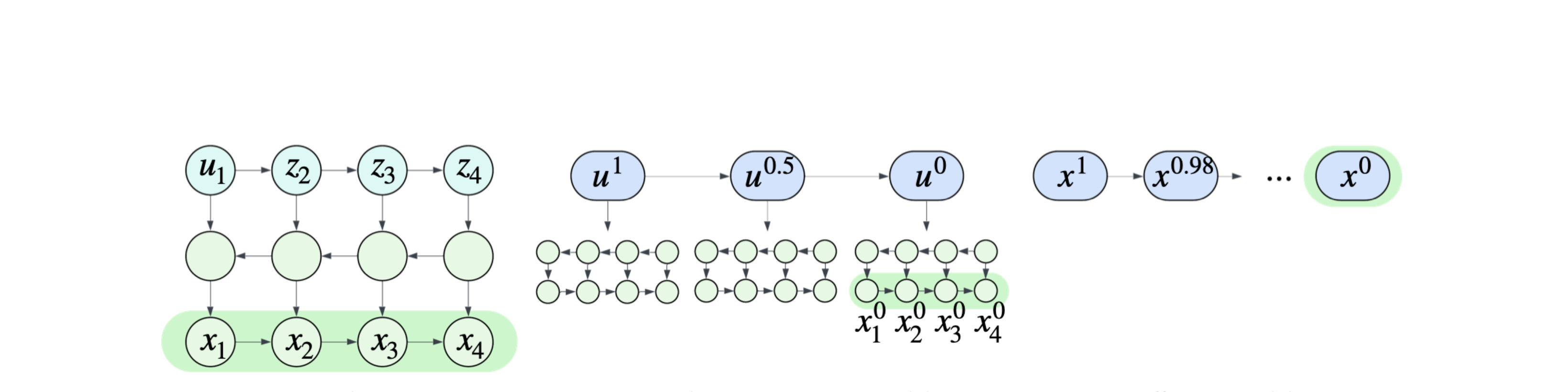
Where NTM sits: NF ↔ diffusion
TARFlow
all depth in a single invertible pass.
all depth in a single invertible pass.
NTM
a few expressive invertible steps — the interpolation.
a few expressive invertible steps — the interpolation.
Diffusion
many small Gaussian steps.
many small Gaussian steps.
Normalizing Trajectory ModelsJ. Gu, T. Chen, Y. Shen, D. Berthelot, S. Zhai, J. Susskind · arXiv 2026
NTM: a normalizing flow at each denoising step
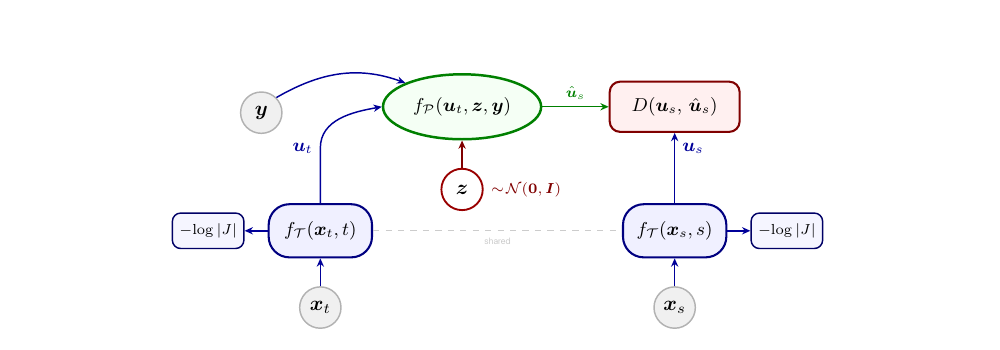
Transporter $f_\mathcal{T}$ — shallow TarFlow-style NVP coupling blocks, applied within a single denoising step. Maps both $x_s$ and $x_t$ into a $u$-space where the conditional is Gaussian-simple.
Predictor $f_\mathcal{P}$ — deep full-attention Transformer, operates across the whole trajectory in parallel. Predicts the Gaussian mean and scale in $u$-space.
$\mathcal{L} = -\log p_\mathcal{P}(u_s \mid u_t) - \log\!\big|\det J_{f_\mathcal{T}}\big|$
Because $f_\mathcal{T}$ is invertible (not just a compressive encoder), this is the exact NLL of $p(x_s \mid x_t)$ — not a surrogate. Trained from scratch or initialized from any pretrained flow-matching model (set $f_\mathcal{T} = \mathrm{id}$).
Normalizing Trajectory ModelsJ. Gu, T. Chen, Y. Shen, D. Berthelot, S. Zhai, J. Susskind · arXiv 2026
Fast inference: trajectory denoising + learned denoiser
Step 1 — trajectory score denoising. The exact NTM likelihood gives a joint score over all timesteps. Its gradient (times the trajectory covariance) denoises the whole generated trajectory at once — no extra data needed.
Step 2 — post-train a lightweight denoiser $g_\phi$. Takes the cleanest predictor output $u_{t_0}$ → directly outputs $\hat x_0$. Trained with MSE against the score-denoised targets from the frozen NTM. Single forward pass at inference — no AR decoding, no backprop.
~9× speedup (0.20 → 1.88 img/s), LPIPS 0.121 vs score denoising. The base NTM's exact likelihood is what makes this distillation data-free and self-supervised.

Normalizing Trajectory ModelsJ. Gu, T. Chen, Y. Shen, D. Berthelot, S. Zhai, J. Susskind · arXiv 2026
NTM matches 50-step diffusion at 4 steps
| Type | Model | GenEval↑ | DPG↑ |
|---|---|---|---|
| DM | SD3-Medium | 0.62 | 84.08 |
| DM | FLUX.1-dev | 0.66 | 83.84 |
| DM | Janus-Pro-7B | 0.80 | 84.19 |
| NF | STARFlow | 0.56 | — |
| NF | NTM (scratch, 256²) | 0.82 | 79.64 |
| NF | NTM (finetune FLUX, 512²) | 0.76 | 83.38 |
From-scratch NTM at 4 steps outperforms FLUX.1-dev and matches Janus-Pro, while retaining exact likelihood. Finetuned NTM (from FLUX.2-klein 4B) closes further at 512².

Normalizing Trajectory ModelsJ. Gu, T. Chen, Y. Shen, D. Berthelot, S. Zhai, J. Susskind · arXiv 2026
Other work in this space
iTARFlow · ICML 2026
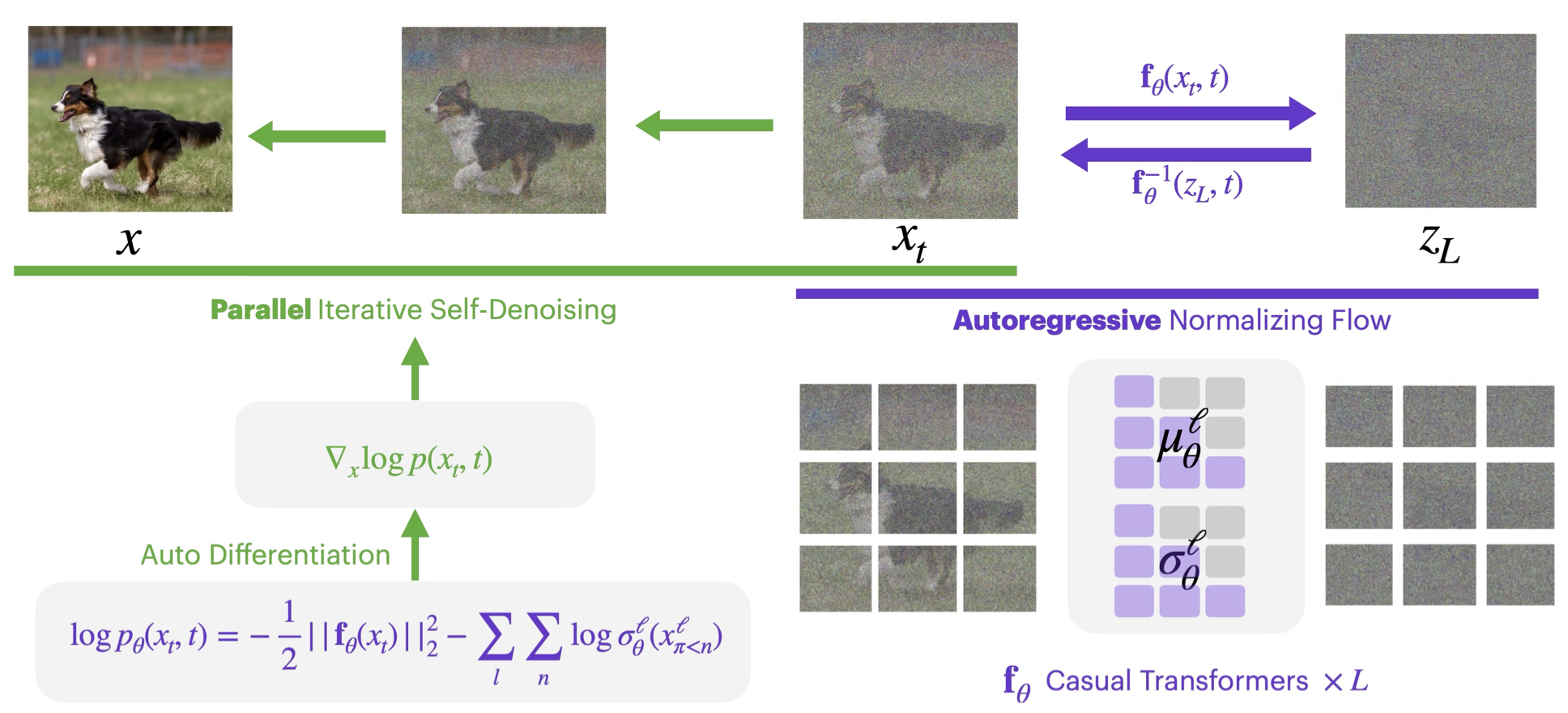
End-to-end NF with iterative diffusion-style denoising at sampling time — competitive ImageNet generation with exact likelihood training.
End-to-end NF with iterative diffusion-style denoising at sampling time — competitive ImageNet generation with exact likelihood training.
TARFlow-LM · NeurIPS 2025
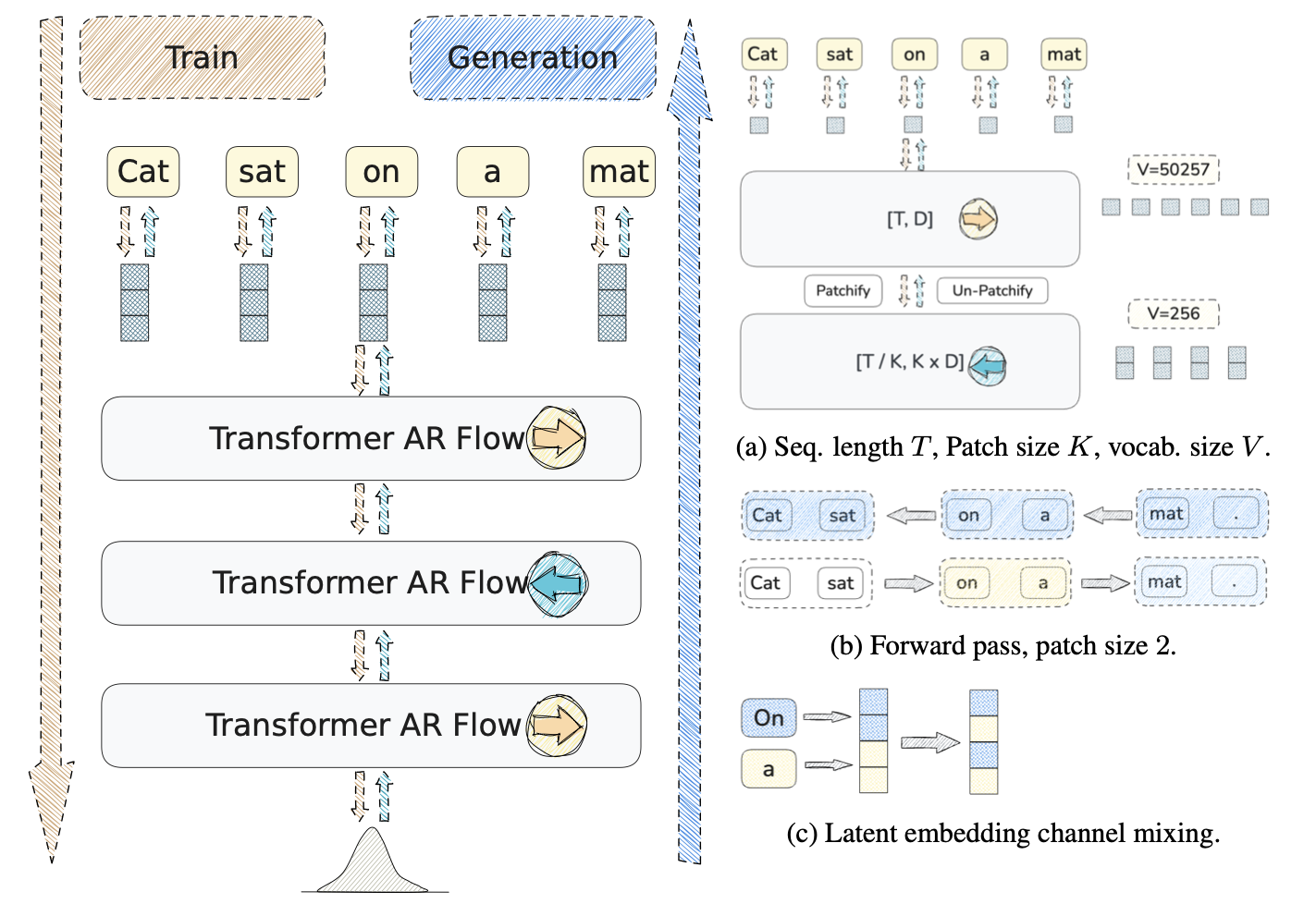
Flexible patch-level AR flows for language — unified text generation via normalizing flows at the token-embedding level.
Flexible patch-level AR flows for language — unified text generation via normalizing flows at the token-embedding level.
STARFlow2 · arXiv 2026
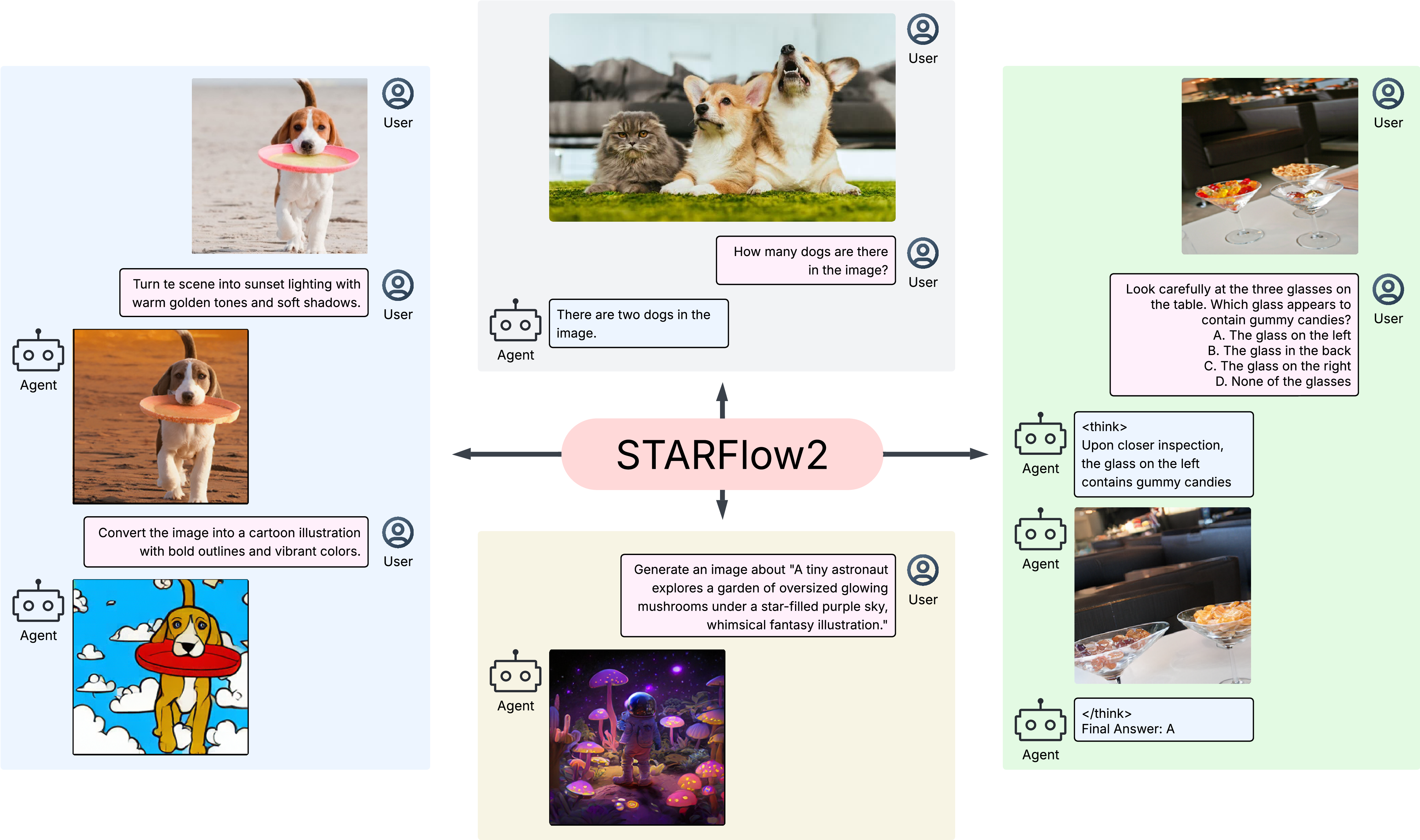
Pretzel 🥨 — a unified multimodal AR model bridging language models and NFs for image understanding, reasoning, and generation in one stream.
Pretzel 🥨 — a unified multimodal AR model bridging language models and NFs for image understanding, reasoning, and generation in one stream.
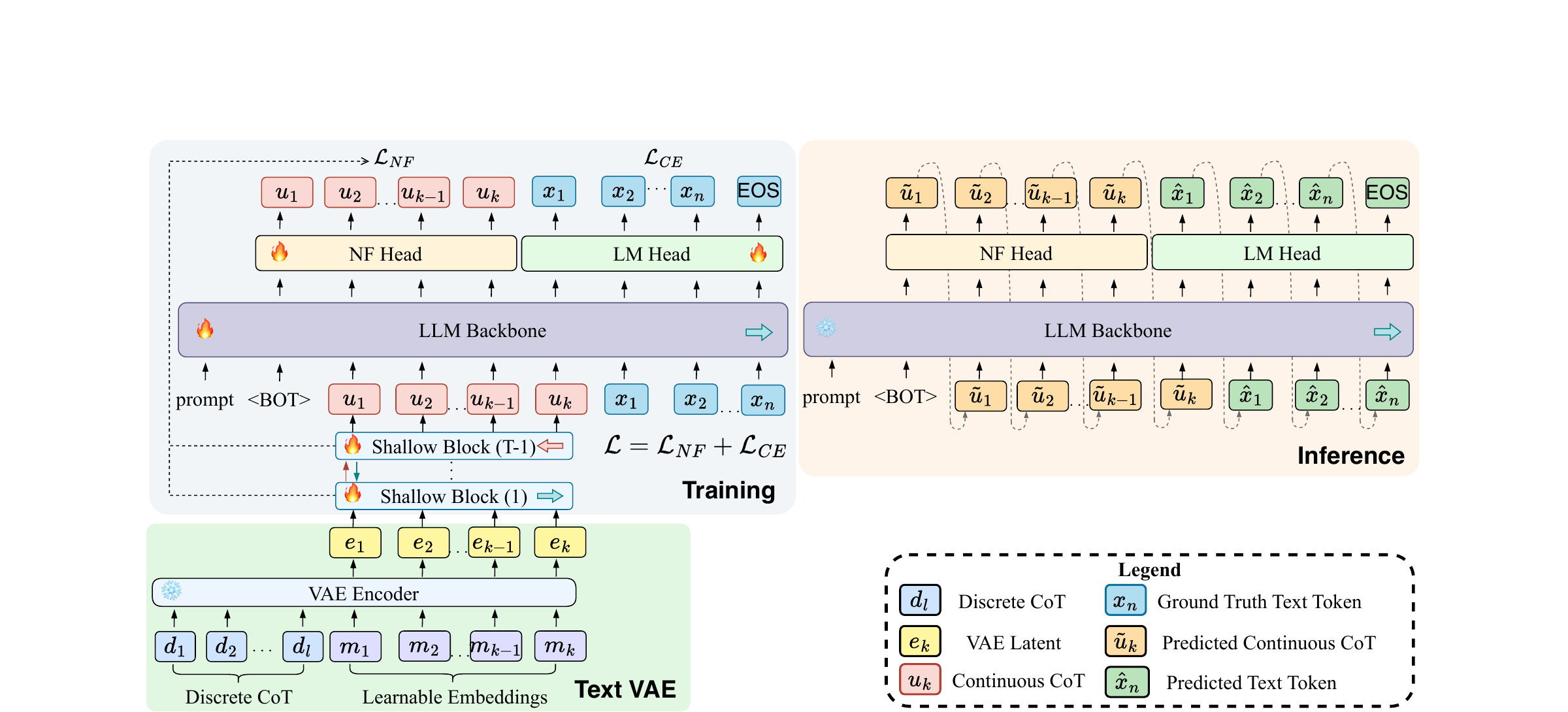
NF-CoT · coming soon
Latent reasoning with normalizing flows — continuous chain-of-thought inside an LLM backbone, with tractable likelihood enabling policy-gradient in thought space.
Latent reasoning with normalizing flows — continuous chain-of-thought inside an LLM backbone, with tractable likelihood enabling policy-gradient in thought space.
Thank you
Are Normalizing Flows good candidates for interactive world models? — so far, maybe.
TARFlow (ICML'25) · STARFlow (NeurIPS'25) · STARFlow-V (CVPR'26) · NTM (arXiv'26) · NFM (arXiv'26)

scan for more
jiataogu.me
Jiatao Gu · GMLR · Penn