Scalable Normalizing Flows
for Visual and
Multimodal Generation
Talk @ T4V Workshop · Jun 3, 2026
Today's best answer: Transfusion-style
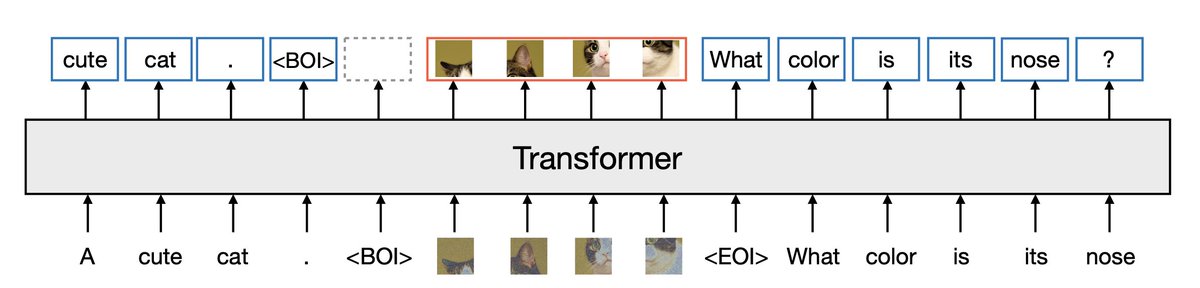
What it gets right. One backbone, mixed-modal sequence, end-to-end training. The de-facto SOTA — Transfusion, Show-o, BAGEL, MoT, Pixart-Σ-style hybrids all sit here.
What it leaves on the table. Two heads, two losses, two regimes. Image gen leaves the AR cache for a 50-step diffusion loop. No shared inference, no exact likelihood for pixels.
Can one AR head handle both modalities — natively, in one stream, with one cache?
Transfusion (Zhou et al., Meta) · Show-o (Xie et al., NUS) · BAGEL (ByteDance) — 2024 – 2025
Normalizing Flows in one slide
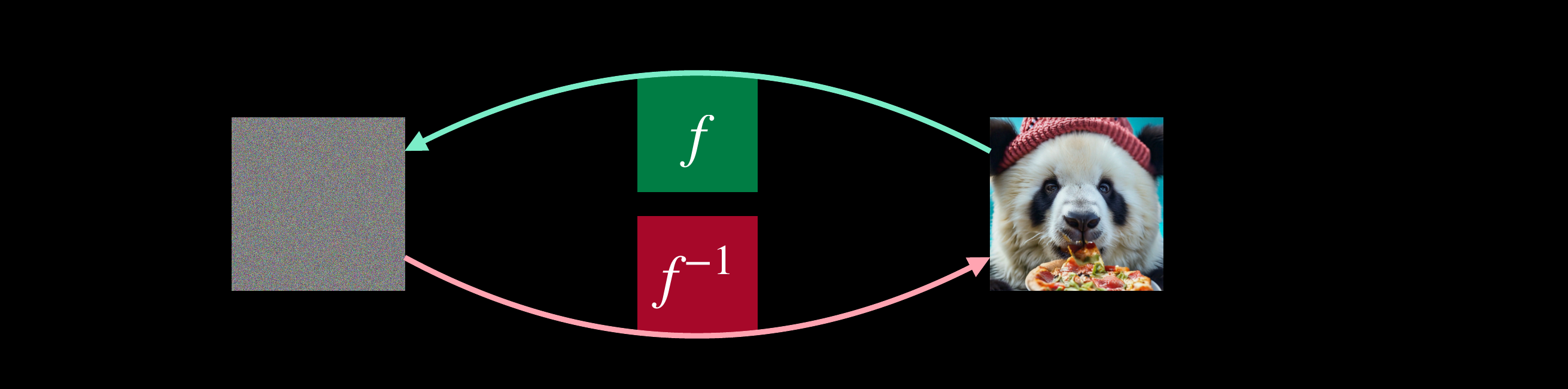
$p(x) = p_0\!\big(f(x)\big)\,\Big|\det \tfrac{\partial f(x)}{\partial x}\Big|,\qquad z=f(x)\ \text{invertible}$
Exact likelihood
trained by exact MLE — one clean objective, no ELBO, no schedule.
trained by exact MLE — one clean objective, no ELBO, no schedule.
Invertible
$x \leftrightarrow z$ is lossless — encoding and generation share the same network.
$x \leftrightarrow z$ is lossless — encoding and generation share the same network.
Continuous
$x \in \mathbb{R}^d$ throughout — no codebook, no quantization, no discretization.
$x \in \mathbb{R}^d$ throughout — no codebook, no quantization, no discretization.
TARFlow — NFs are capable generative models
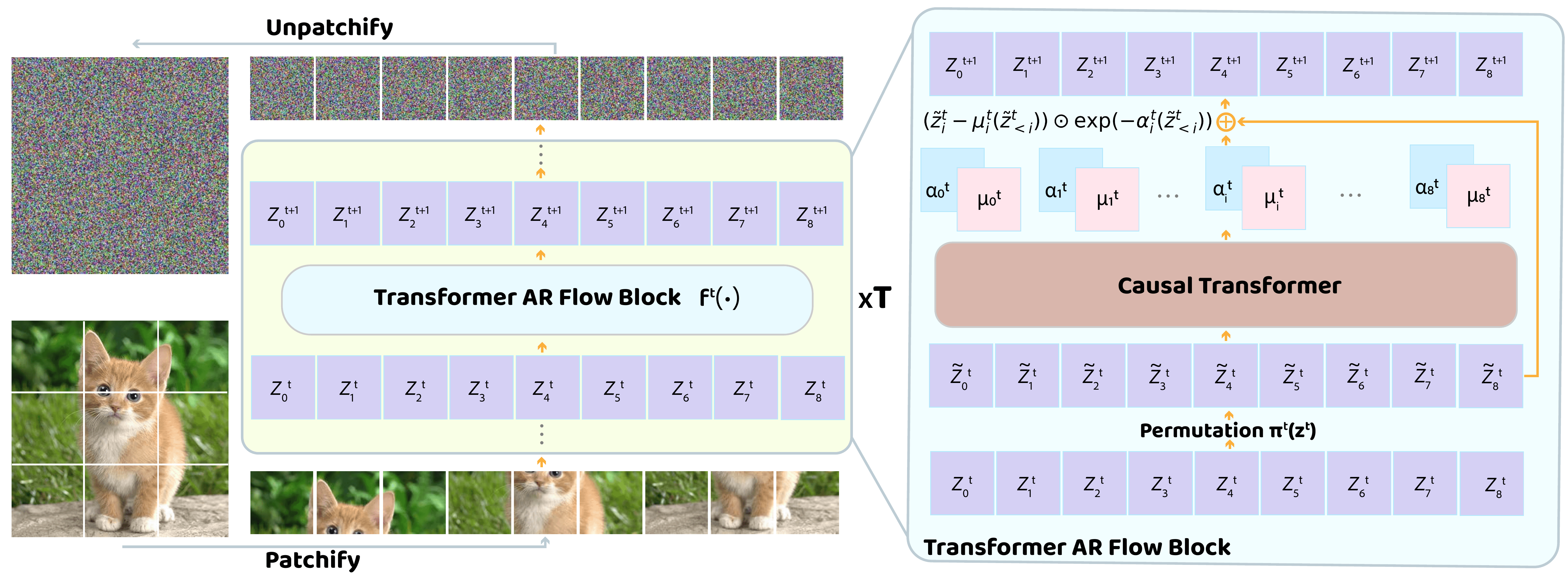
Transformer Autoregressive Flow. A stack of autoregressive Transformer blocks over image patches, alternating scan direction layer-to-layer — a Transformer-based Masked AR Flow.
Three sample-quality tricks. Gaussian noise augmentation in training, a small post-hoc denoiser, and guidance — together close the gap to diffusion samples.
Stand-alone NF. No GAN, no diffusion. Sets new SOTA image likelihoods and diffusion-level samples from a single MLE objective.
Normalizing Flows are Capable Generative ModelsS. Zhai, R. Zhang, P. Nakkiran, D. Berthelot, J. Gu, H. Zheng, T. Chen, M. Bautista, N. Jaitly, J. Susskind · ICML 2025 (Oral)
STARFlow — scaling latent NFs to high resolution

The question. Can a normalizing flow match modern diffusion at 512² & 1024², text-conditional, no quantization?
The answer. Yes — with a deep–shallow latent design, a new guidance recipe, and 3.8B params trained by exact MLE.
First NF at this scale & resolution to approach diffusion sample quality, while keeping exact log-likelihood end-to-end.
STARFlow: Scaling Latent Normalizing Flows for High-resolution Image SynthesisJ. Gu, T. Chen, D. Berthelot, H. Zheng, Y. Wang, R. Zhang, L. Dinh, M. Bautista, J. Susskind, S. Zhai · NeurIPS 2025 (Spotlight)
Architecture: deep + shallow
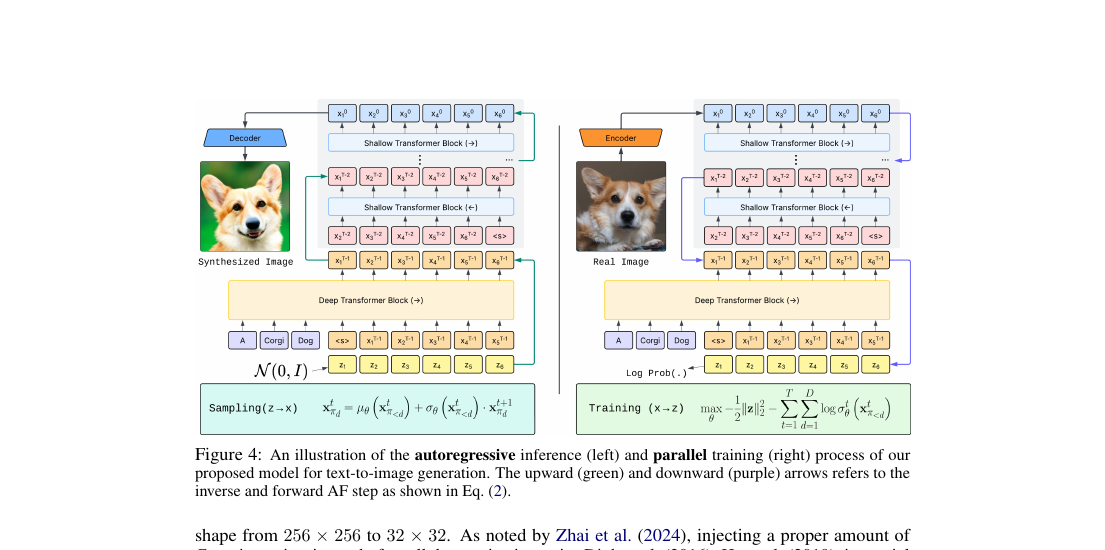
One deep block ($f_D$, 18 layers) — a causal Transformer carrying most of the capacity. Acts like a language model over latent tokens; this is where guidance is applied.
A few shallow blocks ($f_S$, 2 layers each) — alternating scan direction layer-by-layer. Refine local detail; cheap, parallelizable in inverse.
3.8B params (T2I) · 1.4B (class-cond) · DiT-VAE latent at $p=1$ · 1024 tokens for 256², up to 16384 for 1024².
STARFlow: Scaling Latent Normalizing Flows for High-resolution Image SynthesisJ. Gu, T. Chen, D. Berthelot, H. Zheng, Y. Wang, R. Zhang, L. Dinh, M. Bautista, J. Susskind, S. Zhai · NeurIPS 2025 (Spotlight)
FAE — adapt pretrained features for generation
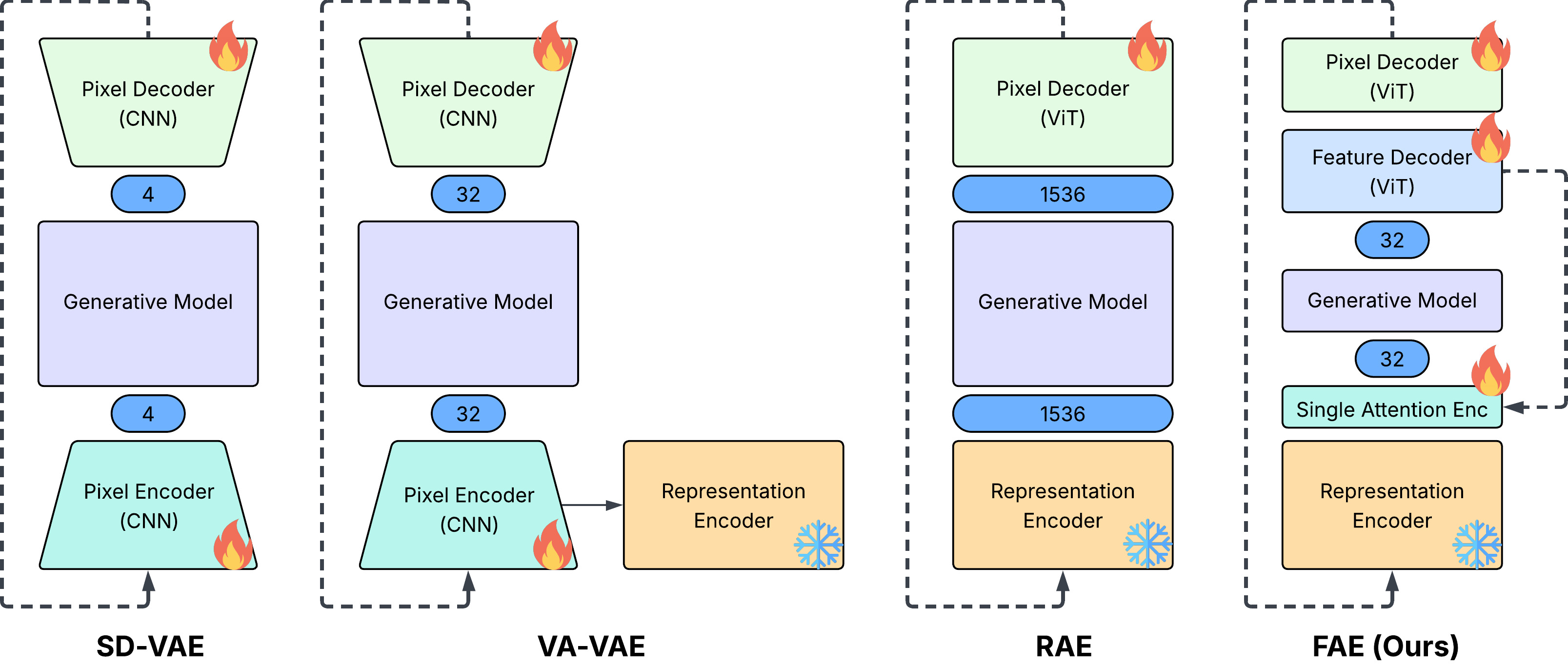
The mismatch. Pretrained encoders (DINOv2, SigLIP) want high-dim latents to model the masked-prediction posterior. Generative models want low-dim latents — small Gaussians, smooth trajectories.
FAE's bet. A Feature AutoEncoder: keep the frozen pretrained encoder, compress its features into a 32-dim generation-friendly code with a single attention layer + linear projection.
Channel dim: SD-VAE 4 · VA-VAE 32 · RAE 1536 · FAE 32 — same compactness as VA-VAE, but built from a pretrained understanding model.
One Layer Is Enough: Adapting Pretrained Visual Encoders for Image GenerationY. Gao, C. Chen, T. Chen, J. Gu · CVPR 2026
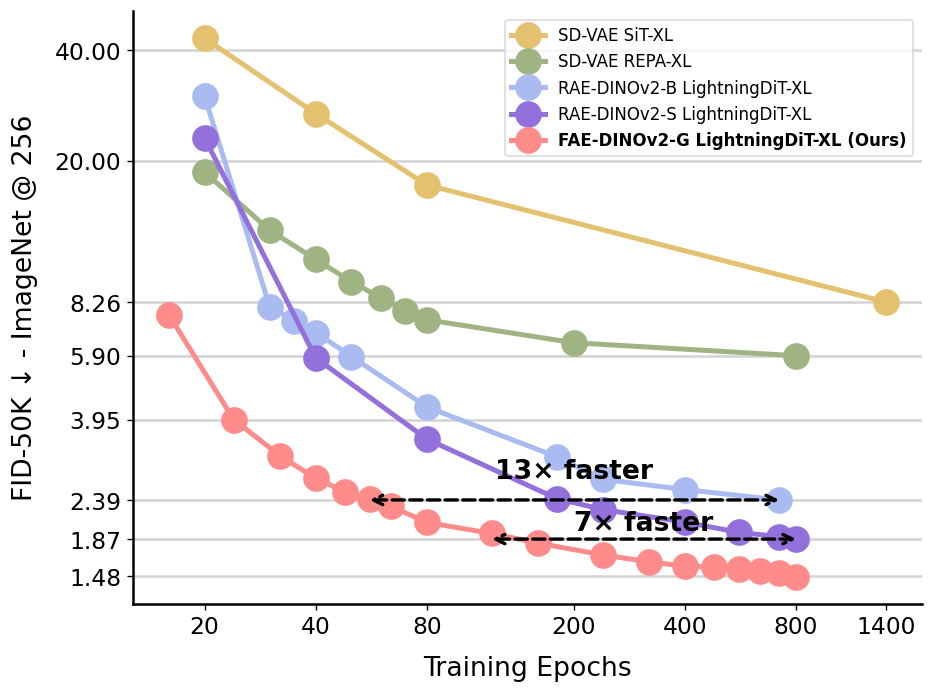
SOTA on ImageNet, 7–13× faster convergence
| ImageNet 256² · FID-50K | 80 ep | 800 ep |
|---|---|---|
| FAE-DINOv2-G + LightningDiT-XL | 2.08 | 1.48 |
| ↳ + CFG | 1.70 | 1.29 |
SOTA without CFG. 1.48 FID at 800 epochs — best reported for ImageNet 256² without classifier-free guidance.
7–13× faster than RAE-DINOv2-S/B at matched FID — the minimal-design adapter beats heavier ones.
One Layer Is Enough: Adapting Pretrained Visual Encoders for Image GenerationY. Gao, C. Chen, T. Chen, J. Gu · CVPR 2026
FAE plugs into Normalizing Flows too
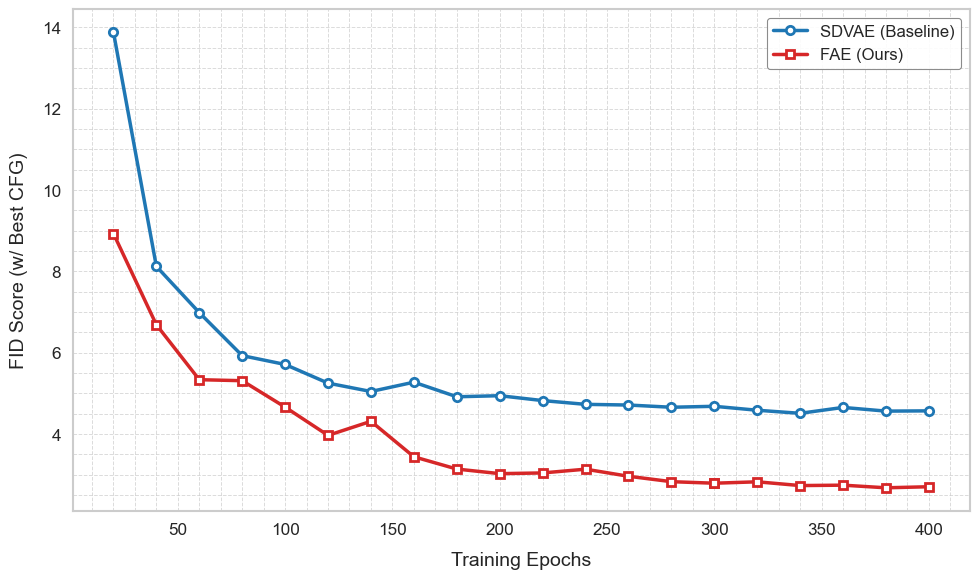
Same recipe, NF generator. Train STARFlow (1.4B params) on FAE-DINOv2-G latents — same patch size, same sequence length as SD-VAE baseline for fair comparison.
| STARFlow · ImageNet 256² | FID @ 400 ep |
|---|---|
| SD-VAE baseline | 4.51 |
| FAE (DINOv2-g/14) | 2.67 |
Universal. The same compact pretrained-feature latent that won on diffusion also speeds up & sharpens NF generation — no NF-specific changes.
One Layer Is Enough: Adapting Pretrained Visual Encoders for Image GenerationY. Gao, C. Chen, T. Chen, J. Gu · CVPR 2026
Closing the gap to diffusion
| ImageNet · FID-50K | 256² | 512² |
|---|---|---|
| DiT-XL (diffusion) | 3.60 | — |
| STARFlow (1.4B) | 2.40 | 3.00 |
| Text-to-image (CC12M) | GenEval | COCO FID-30K |
|---|---|---|
| STARFlow (3.8B) | 0.56 | 9.1 |
First NF to outperform a strong diffusion peer on class-conditional ImageNet — and the first to scale text-conditional NFs to large data, with exact likelihood throughout.

STARFlow: Scaling Latent Normalizing Flows for High-resolution Image SynthesisJ. Gu, T. Chen, D. Berthelot, H. Zheng, Y. Wang, R. Zhang, L. Dinh, M. Bautista, J. Susskind, S. Zhai · NeurIPS 2025 (Spotlight)
STARFlow-V — NFs across time
Global deep + local shallow over a spatiotemporal latent — same recipe as STARFlow, now causal across frames.
One model, three tasks. T2V / I2V / V2V from a single weights-set, no fine-tuning — invertibility for free.
Likelihood & long horizons. Exact log-likelihood over video; stable to 30 s, 6× past the 5 s training window.
STARFlow-V: End-to-End Video Generative Modeling with Normalizing FlowsJ. Gu, Y. Shen, T. Chen, L. Dinh, Y. Wang, M. Bautista, D. Berthelot, J. Susskind, S. Zhai · CVPR 2026 (Highlight)
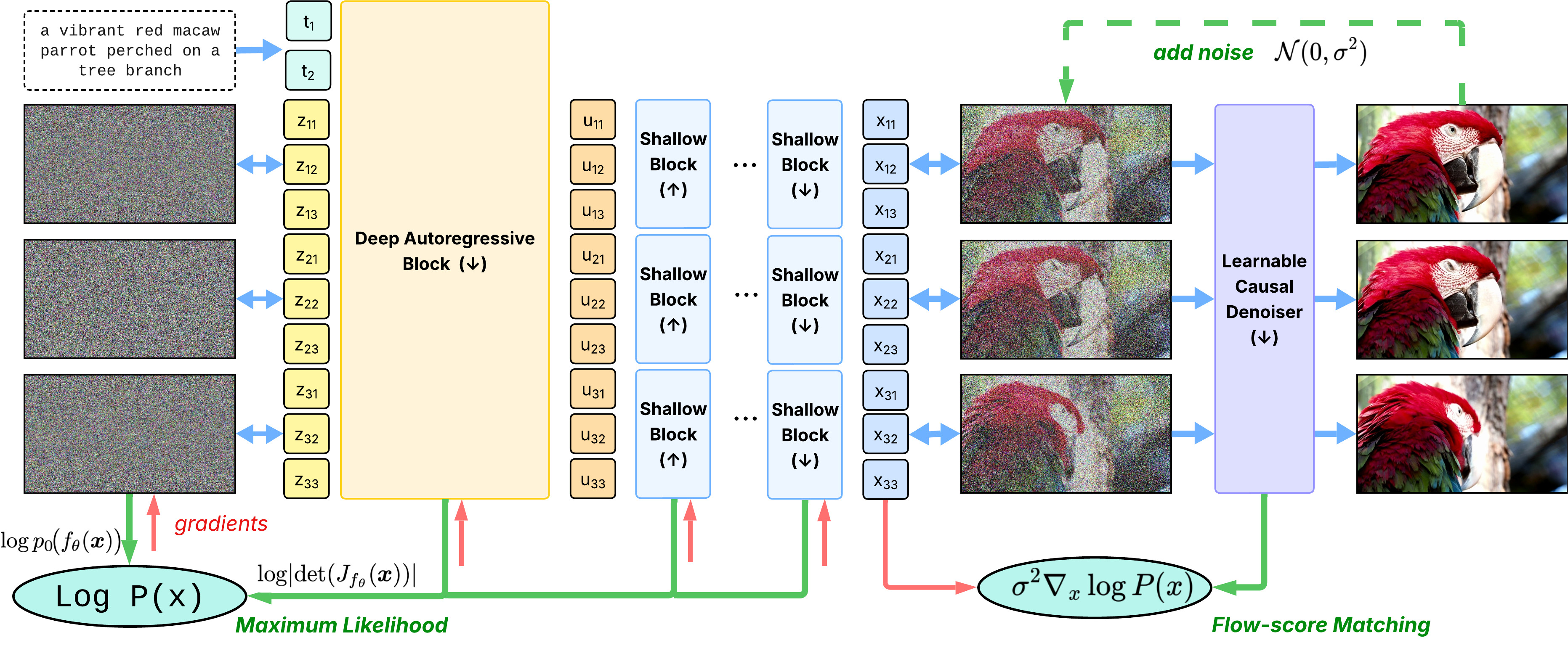
STARFlow2 — bridging LMs and NFs
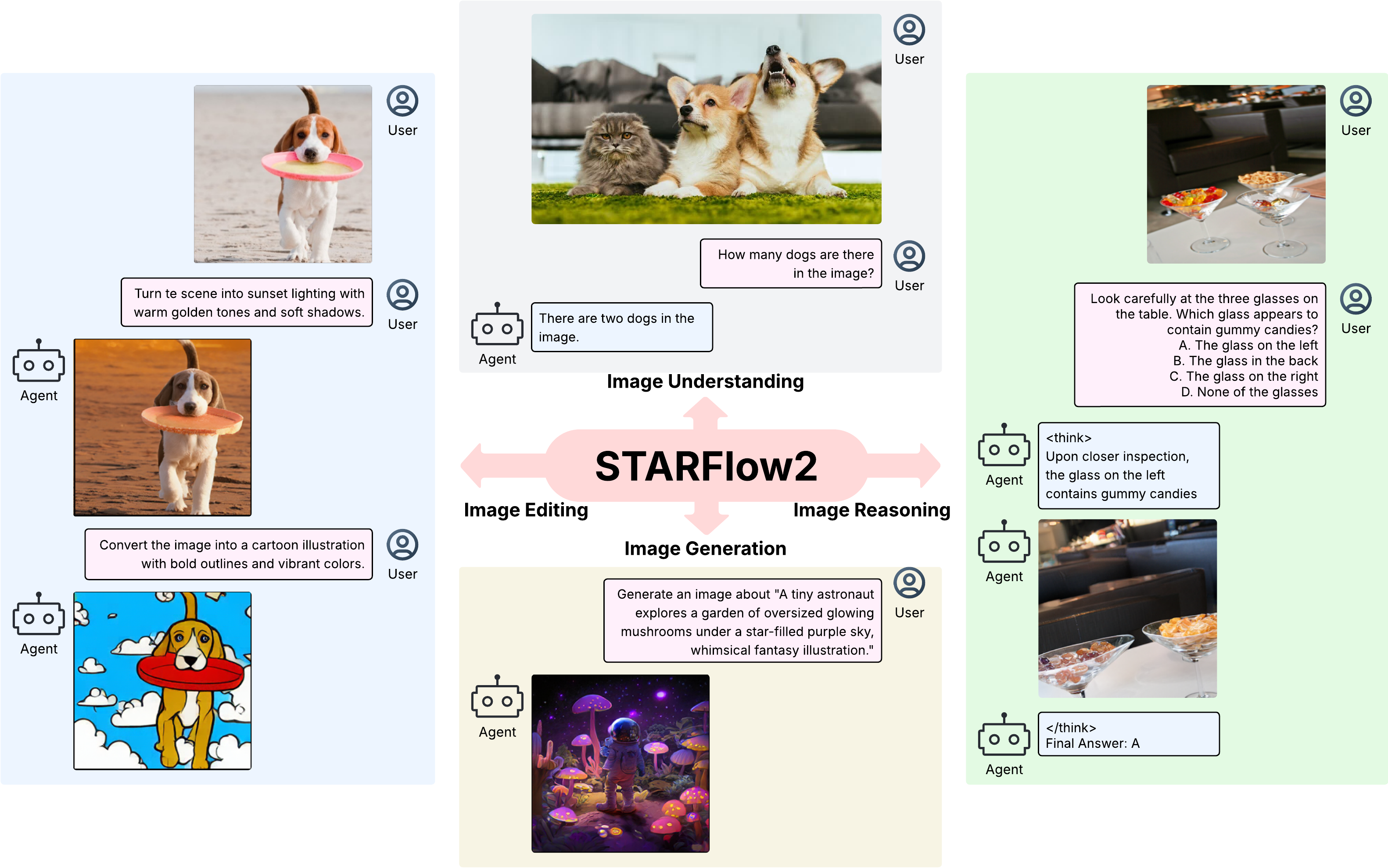
The setup. Build a single autoregressive multimodal model that (D1) preserves a pretrained VLM's understanding, (D2) generates continuous high-fidelity images, (D3) stays one causal stream with shared KV-cache.
The key observation. An autoregressive normalizing flow is an autoregressive Transformer. Same causal mask, same cache, same L→R. That equivalence is the architecture.
The answer. Pretzel 🥨 — vertically interleave a frozen VLM stream with a trainable TARFlow stream under a shared causal mask.
STARFlow2: Bridging Language Models and Normalizing Flows for Unified Multimodal GenerationY. Shen, T. Chen, Y. Gao, Y. Zhang, Y. Wang, M. Bautista, S. Zhai, J. Susskind, J. Gu · arXiv 2026
Pretzel 🥨 — vertical interleaving
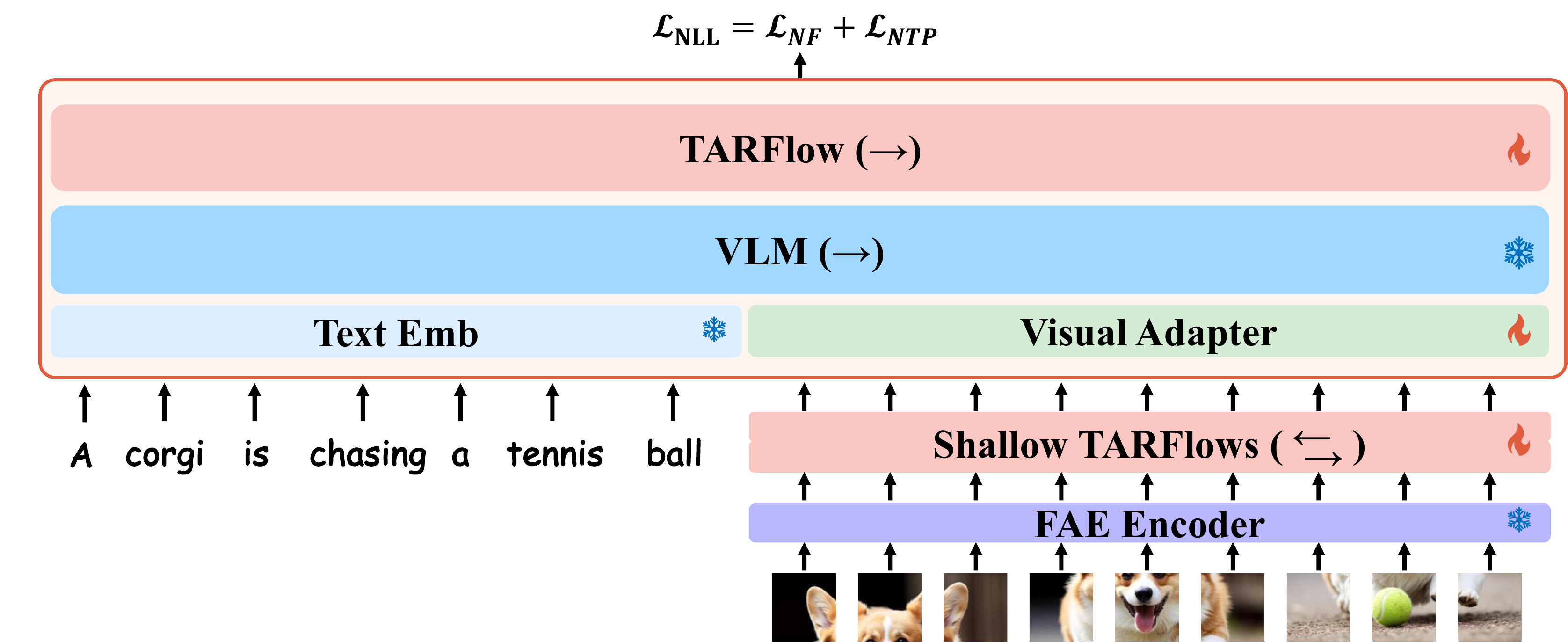
VLM stream ❄️
Frozen Qwen2.5-VL-7B-Instruct. Pretrained understanding kept intact (D1).
Frozen Qwen2.5-VL-7B-Instruct. Pretrained understanding kept intact (D1).
TARFlow stream 🔥
Trainable AR-flow over visual latents. High-fidelity continuous generation (D2).
Trainable AR-flow over visual latents. High-fidelity continuous generation (D2).
Vertical residual skips
Cross-modal fusion at every position under one shared causal mask (D3).
Cross-modal fusion at every position under one shared causal mask (D3).
$\mathcal{L}_\text{NLL} = \mathcal{L}_\text{NF}\ (\text{visual})\ +\ \lambda\,\mathcal{L}_\text{NTP}\ (\text{text})$
STARFlow2: Bridging Language Models and Normalizing Flows for Unified Multimodal GenerationY. Shen, T. Chen, Y. Gao, Y. Zhang, Y. Wang, M. Bautista, S. Zhai, J. Susskind, J. Gu · arXiv 2026
Why not MoT / BAGEL? — a negative result
Mode A: freeze VLM, train TARFlow branch only.
Generation collapses (left). TARFlow can't enter the VLM's KV-cache as reusable context — horizontal routing keeps streams blind to each other.
Generation collapses (left). TARFlow can't enter the VLM's KV-cache as reusable context — horizontal routing keeps streams blind to each other.
Mode B: fine-tune VLM jointly.
Understanding degrades sharply — MME drops to ~30. Pretrained VLM capabilities are washed out by the new visual loss.
Understanding degrades sharply — MME drops to ~30. Pretrained VLM capabilities are washed out by the new visual loss.
Pretzel fixes both. Vertical residuals: VLM stays frozen (no understanding loss), TARFlow lives inside the same causal mask (true cross-modal context).

MoT-style generations under mode A — degenerate, mode-collapsed.
STARFlow2: Bridging Language Models and Normalizing Flows for Unified Multimodal GenerationY. Shen, T. Chen, Y. Gao, Y. Zhang, Y. Wang, M. Bautista, S. Zhai, J. Susskind, J. Gu · arXiv 2026
Three-stage curriculum
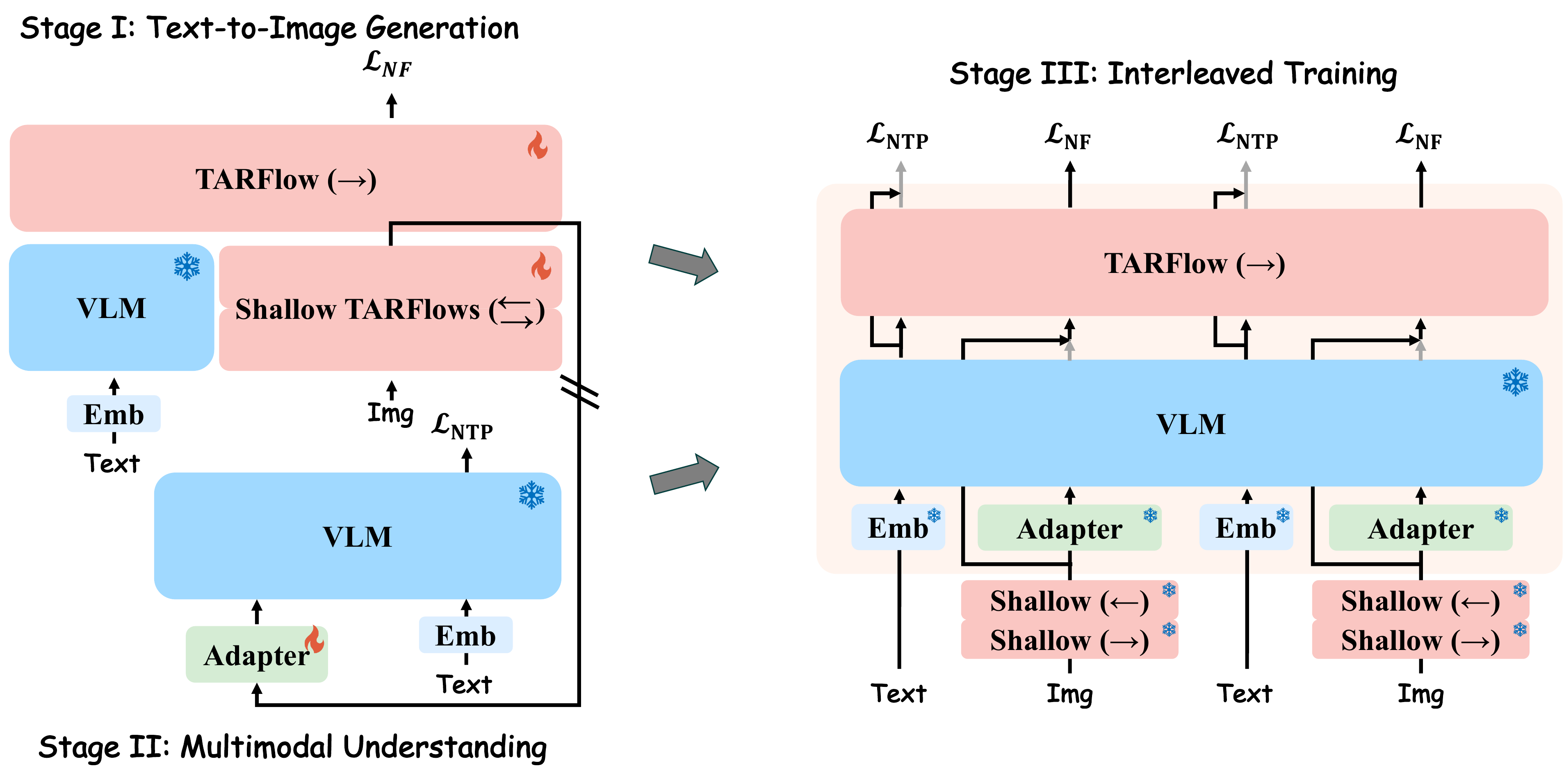
Stage 1 · T2I
Train TARFlow stream from scratch on ~800M text→image pairs. VLM, FAE frozen. Establish visual generation backbone.
Train TARFlow stream from scratch on ~800M text→image pairs. VLM, FAE frozen. Establish visual generation backbone.
Stage 2 · I2T adapter
Train only the visual adapter (zero-init) on ~200M image→text. Align FAE latents with the VLM's representation space.
Train only the visual adapter (zero-init) on ~200M image→text. Align FAE latents with the VLM's representation space.
Stage 3 · interleaved joint
Activate vertical skips, train all on ~80M interleaved examples (gen + edit + understand). Joint $\mathcal{L}_\text{NF}+\lambda\mathcal{L}_\text{NTP}$.
Activate vertical skips, train all on ~80M interleaved examples (gen + edit + understand). Joint $\mathcal{L}_\text{NF}+\lambda\mathcal{L}_\text{NTP}$.
3.6B trainable params · Qwen2.5-VL-7B + FAE frozen throughout · zero-init visual adapter for safe cross-modal coupling.
STARFlow2: Bridging Language Models and Normalizing Flows for Unified Multimodal GenerationY. Shen, T. Chen, Y. Gao, Y. Zhang, Y. Wang, M. Bautista, S. Zhai, J. Susskind, J. Gu · arXiv 2026
One causal stream — text and pixels in the same KV-cache

No re-encoding. Generated images are projected into the VLM embedding space and reused as ordinary tokens by later steps — text and visual positions share the cache.
No diffusion loop. Each visual position is a single AR Gaussian, not a 50-step ODE. Same per-token cost as language.
Mix freely. Text → image → text → image, in one rollout, in one cache, in one model. The dream from slide 2.
STARFlow2: Bridging Language Models and Normalizing Flows for Unified Multimodal GenerationY. Shen, T. Chen, Y. Gao, Y. Zhang, Y. Wang, M. Bautista, S. Zhai, J. Susskind, J. Gu · arXiv 2026
From prompts to edits — one model

Text-to-image · same weights, no separate generation head

Multi-turn editing · invertibility = encode & decode share the network
STARFlow2: Bridging Language Models and Normalizing Flows for Unified Multimodal GenerationY. Shen, T. Chen, Y. Gao, Y. Zhang, Y. Wang, M. Bautista, S. Zhai, J. Susskind, J. Gu · arXiv 2026
Other works in the NF line

NTM
Each reverse step = a conditional NF. 4-step generation with exact likelihood across the whole trajectory.
arXiv 2026
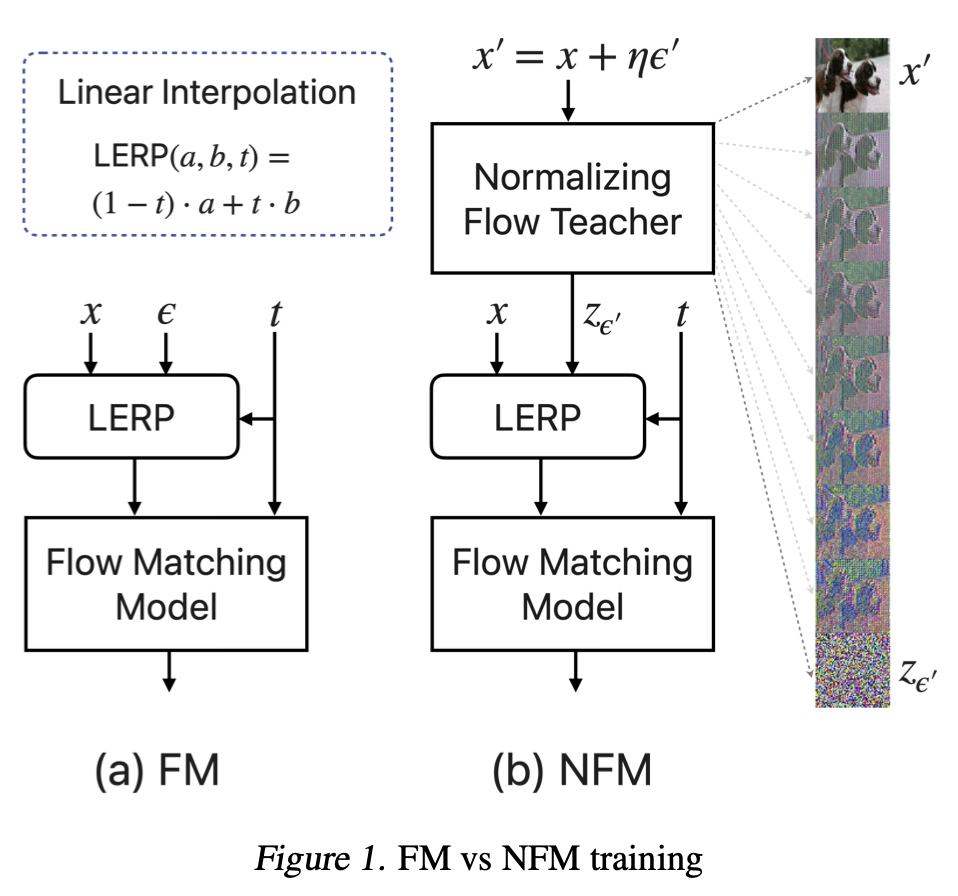
NFM
Distill an AR-NF's deterministic noise↔data coupling into a flow-matching student. Beats independent & OT couplings.
arXiv 2026
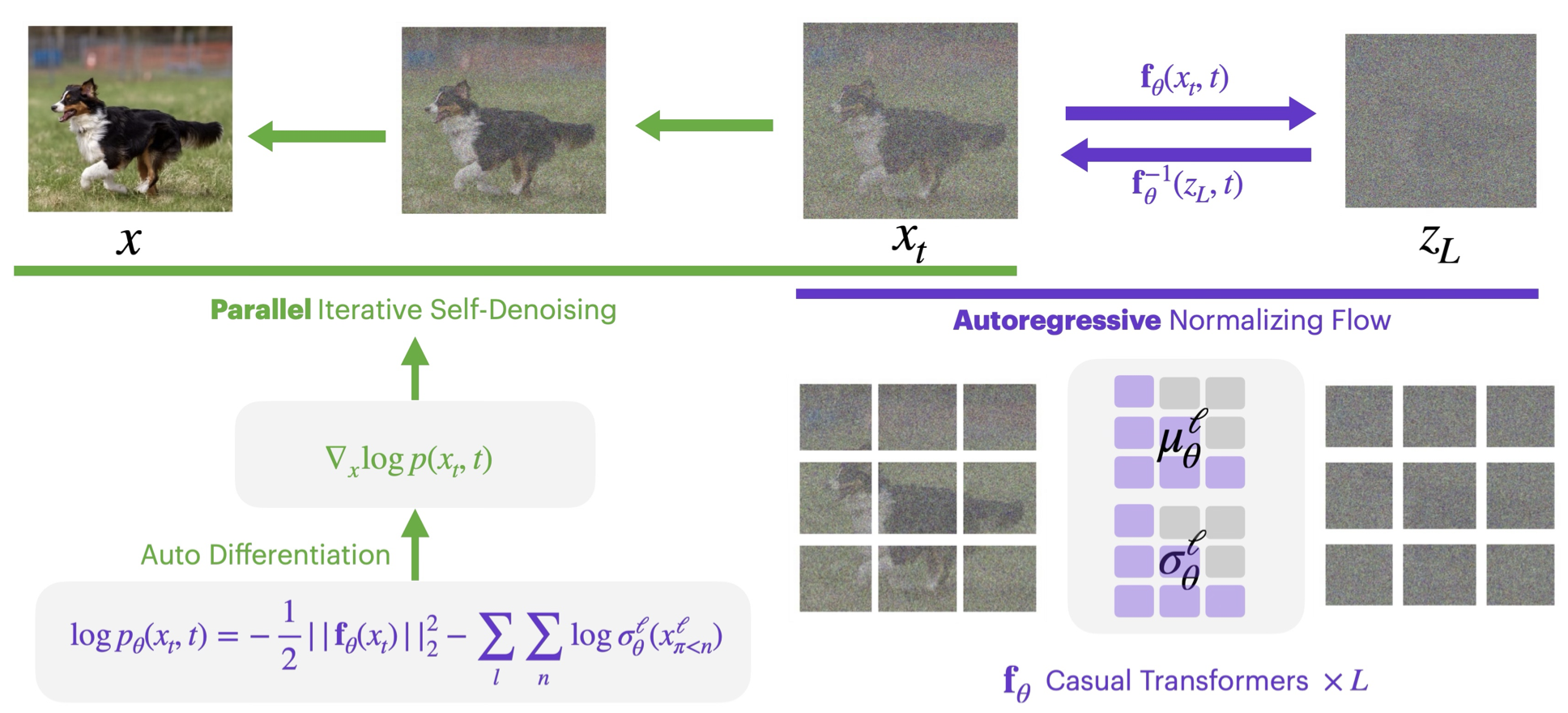
iTARFlow
End-to-end NF training + diffusion-style iterative denoising at sampling. Competitive on ImageNet 64 / 128 / 256.
ICML 2026
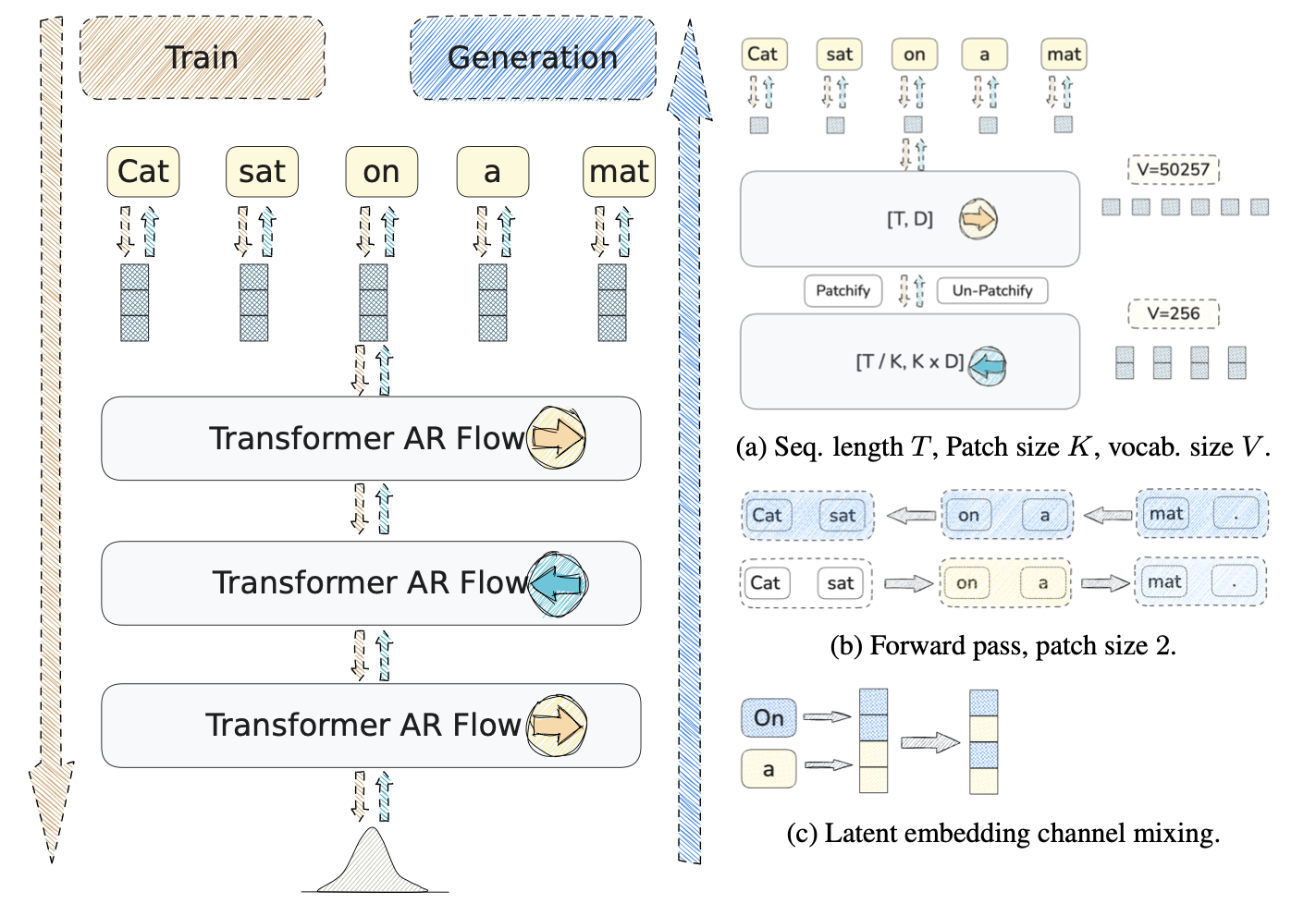
TarFlowLM
Continuous AR over text with a TARFlow-style Gaussian head — language modeling without the softmax bottleneck.
NeurIPS 2025
coming soon
NF-CoT
Continuous chain-of-thought via AR-NF — latent reasoning. Bridge to the KnowledgeMR talk.
in prep.
Thank you
Scalable Normalizing Flows for Visual & Multimodal Generation — one AR stream, exact likelihood, no quantization.
TARFlow (ICML'25) · STARFlow (NeurIPS'25) · STARFlow-V (CVPR'26) · FAE (CVPR'26) · STARFlow2 (arXiv'26)

scan for more
jiataogu.me
Jiatao Gu · GMLR · Penn