Should Embodied Intelligence
Care About 3D?
Talk @ EmbodiedAIinLife Workshop · Jun 3, 2026
"Should you care about 3D?" — domain by domain
An influential framing — domain by domain.

I basically agree. A sharp framing — and very reasonable.
The row this talk wants to look at more carefully is Robotics — given today's data picture.
Three works, one arc
3D as an interface — three roles for the same primitive.
PointAction — dynamic point trajectories as a universal action interface. arXiv 2606.03943
OmniGuide — differentiable 3D energy fields steer any VLA at test-time. arXiv 2026

PhysCtrl — point-trajectory physics-grounded video on 4 materials. NeurIPS 2025
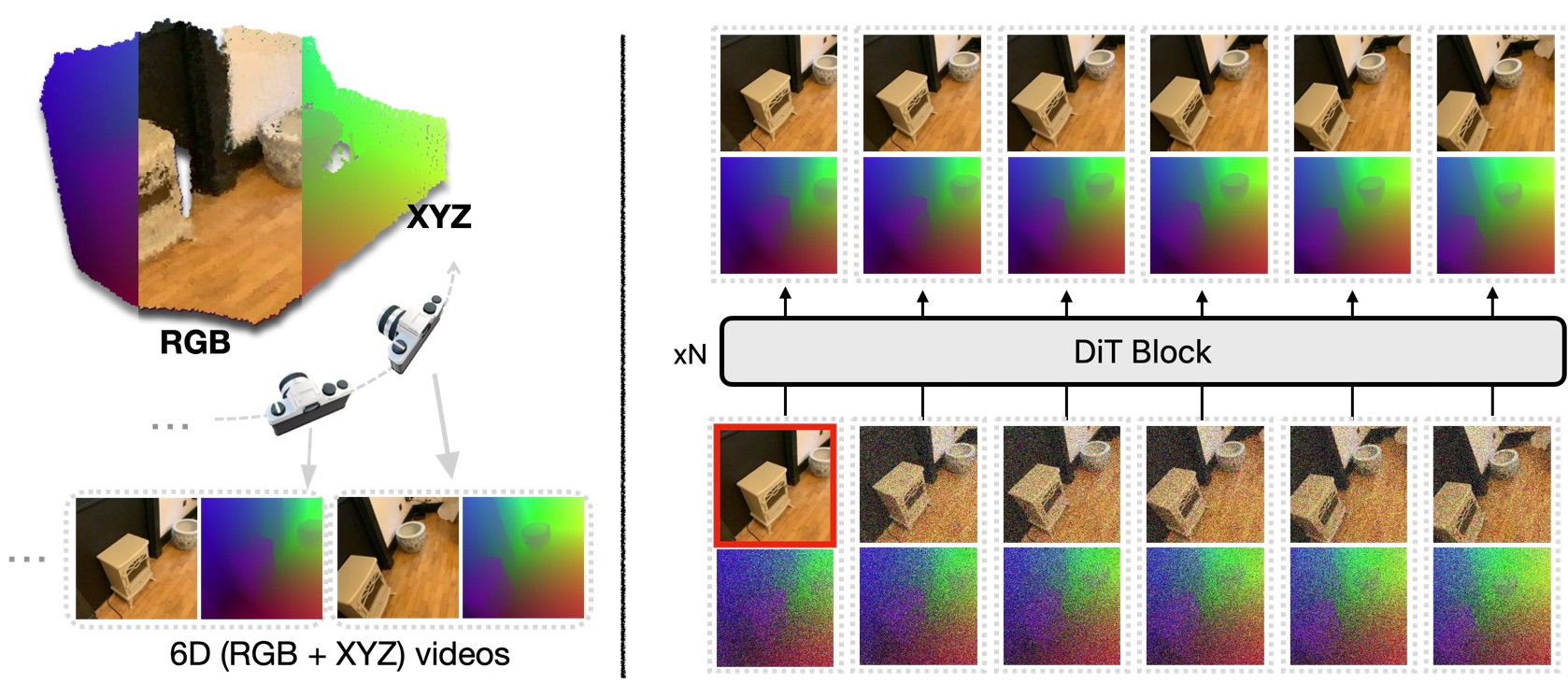
Building on prior work — WVD (CVPR'25, Highlight): 3D as a supervision signal for video models.
PointAction — 3D points as a universal action representation
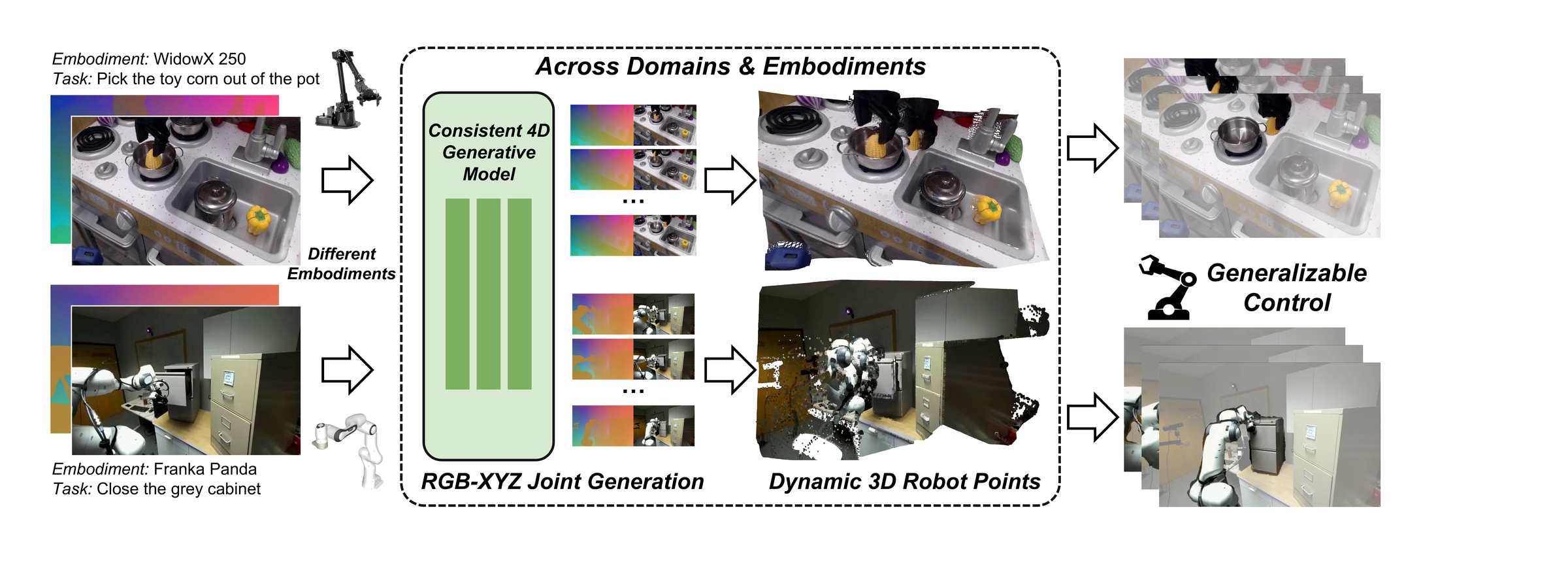
Embodiment-agnostic point trajectories as the interface between video prediction and robot control.
Prior work — WVD: 3D as supervision, not output
PointAction extends this from static images to dynamic point trajectories — and connects them to action.
The trick: pixel-aligned 3D coordinates
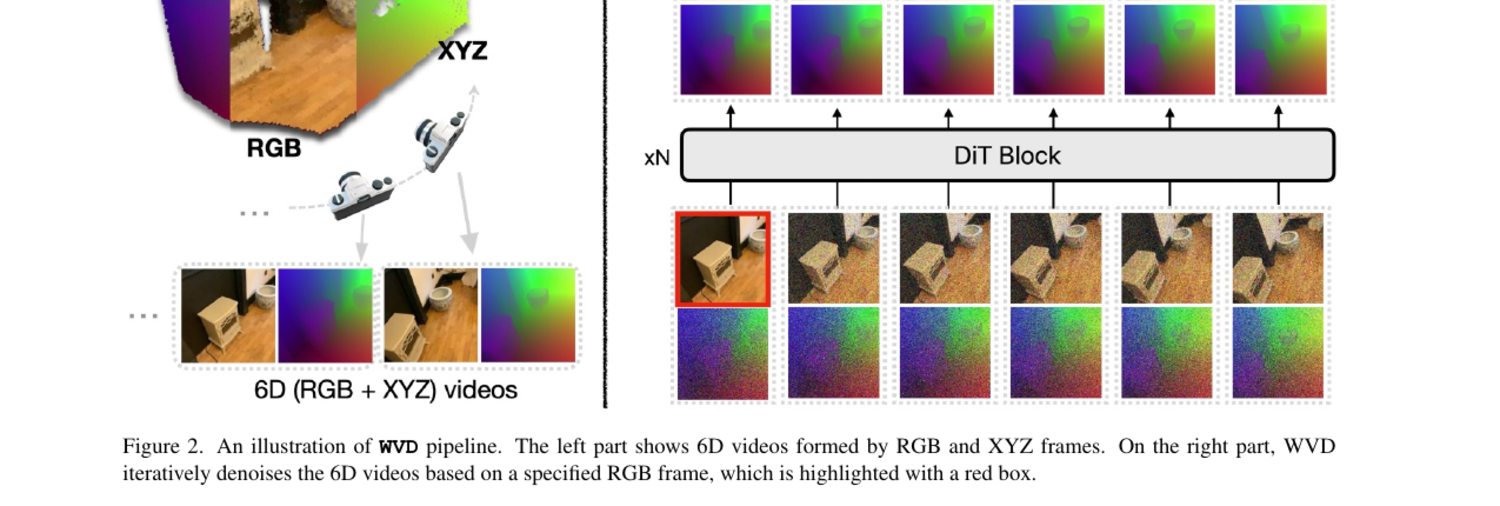
Stage 1: joint RGB + XYZ rollout
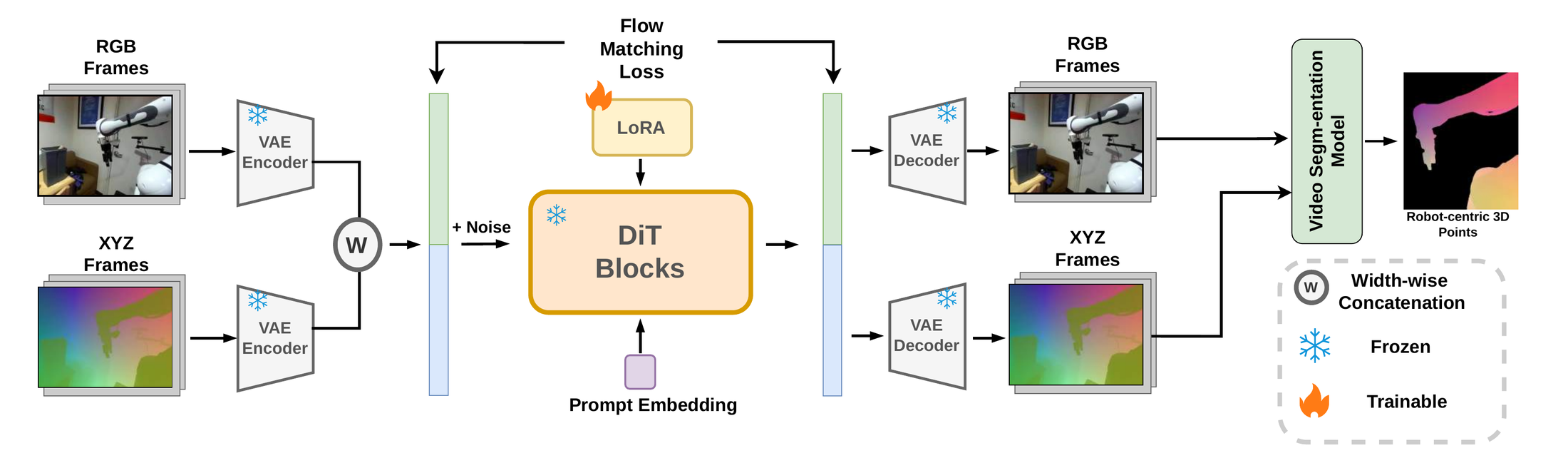
Stage 2: point trajectories → low-level actions
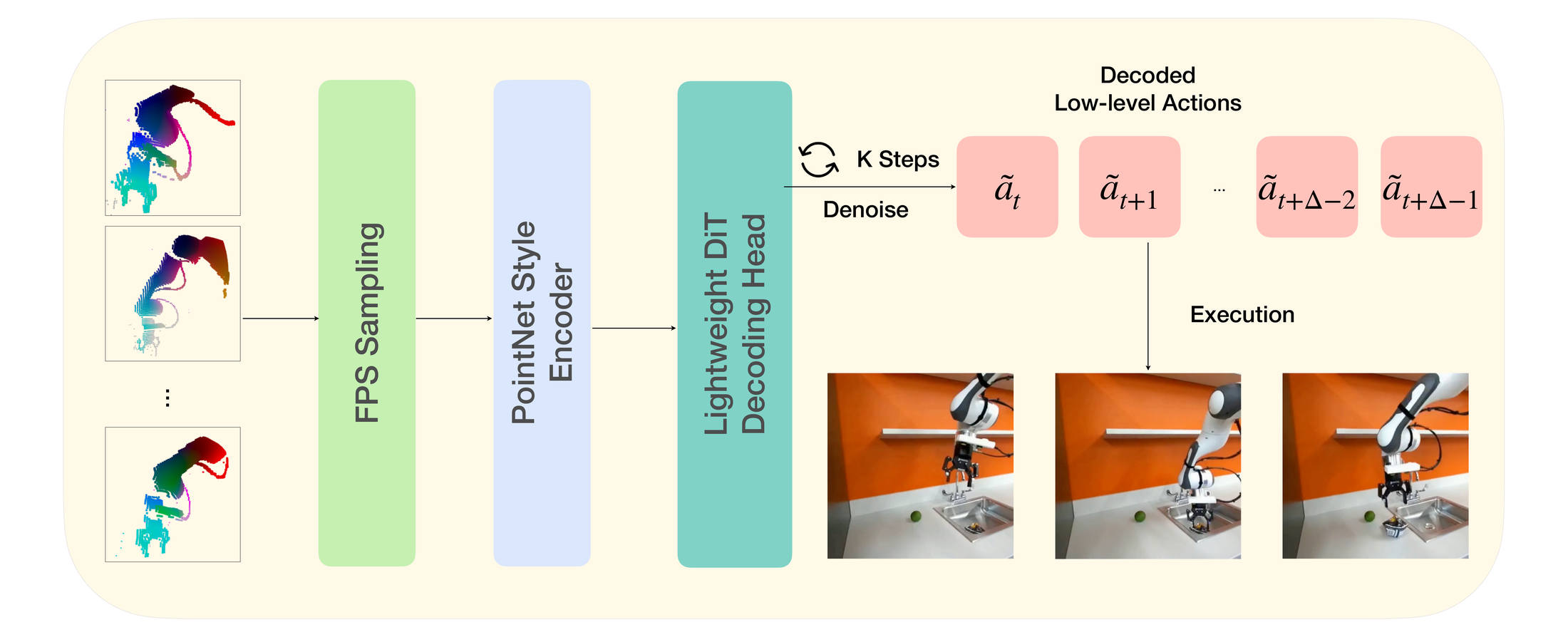
A small amount of paired robot data is only needed to train this decoder — the world model is unchanged across embodiments.
OmniGuide — 3D guidance fields for any VLA
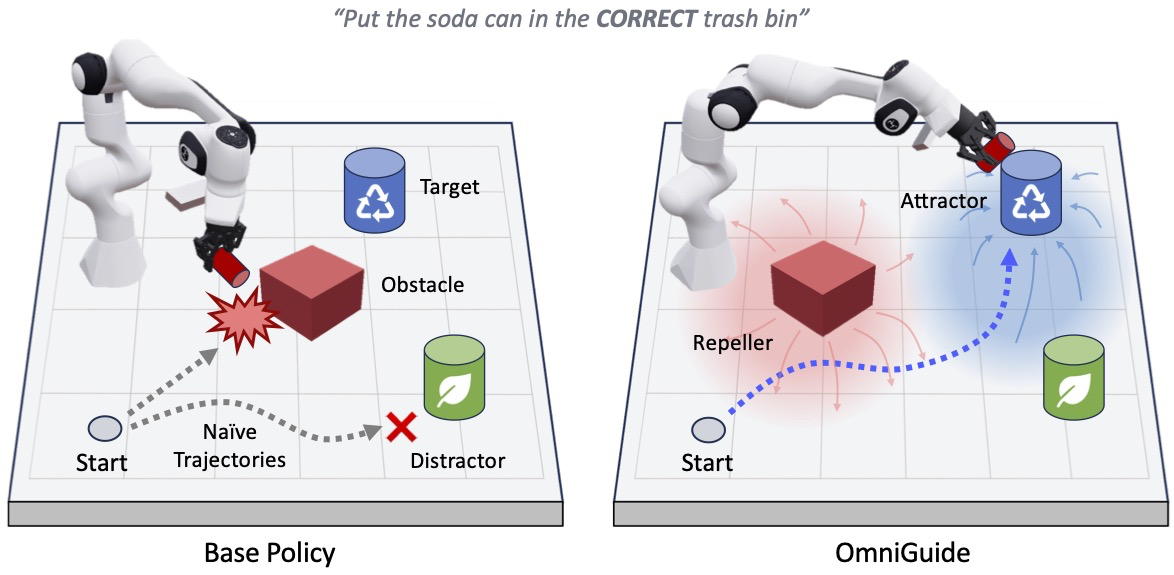
Test-time scaffolding. Steer any diffusion-based VLA with task-specific 3D attractors and repellers — no extra robot data, no retraining.
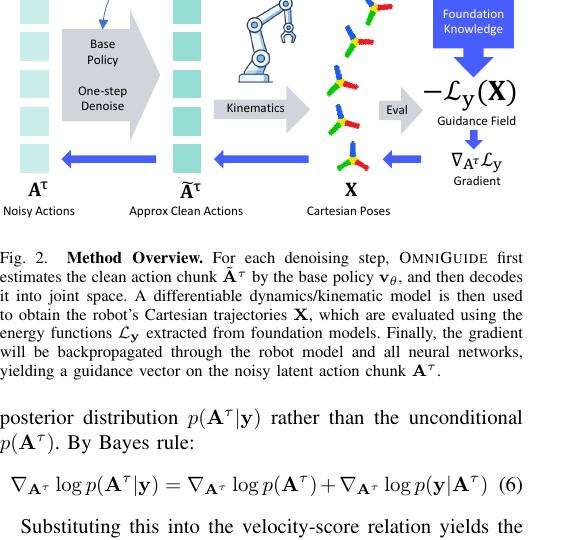
How the gradient gets in
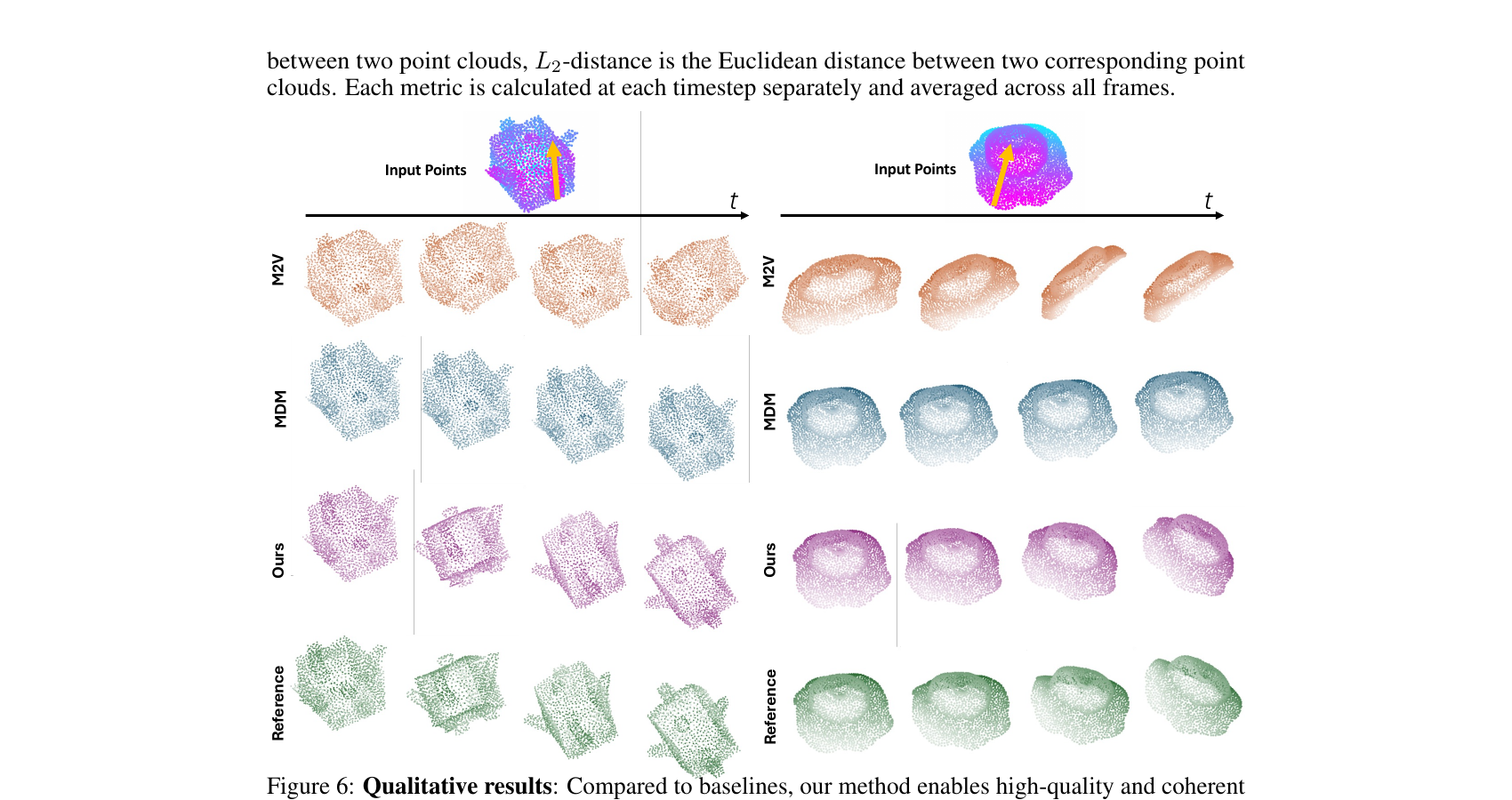
How PhysCtrl works — point cloud → physics → video
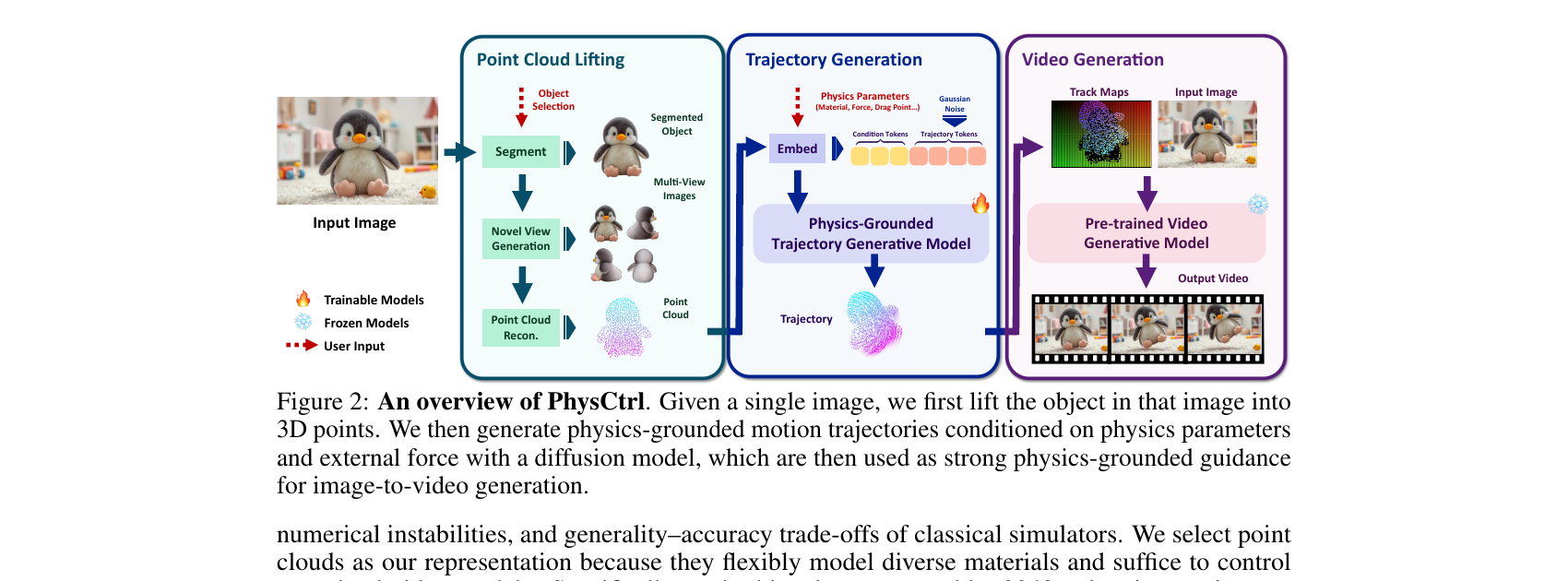
Four materials — elastic, sand, plasticine, rigid
Thank you
Should embodied intelligence care about 3D? — maybe — at least as an interface, for now.
WVD (CVPR'25) · PointAction (arXiv 2606.03943) · OmniGuide (arXiv'26) · PhysCtrl (NeurIPS'25)
