Probabilistic
Continuous Reasoning
Latent thoughts with a real density — and on-policy RL in latent space
KnowledgeMR Workshop · Jun 4, 2026 · 11:00–11:40
Latent thoughts with a real density — and on-policy RL in latent space
KnowledgeMR Workshop · Jun 4, 2026 · 11:00–11:40
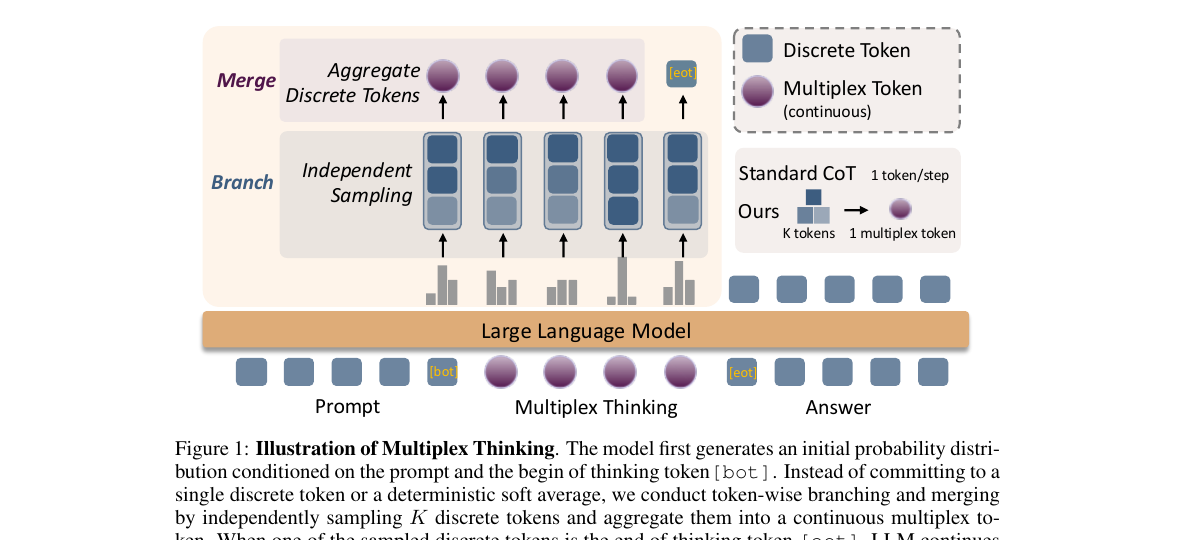
Continuous in the embedding space — but each branch is a real discrete sample, so the per-step policy distribution is preserved. This is what makes Multiplex probabilistic, unlike Soft Thinking.
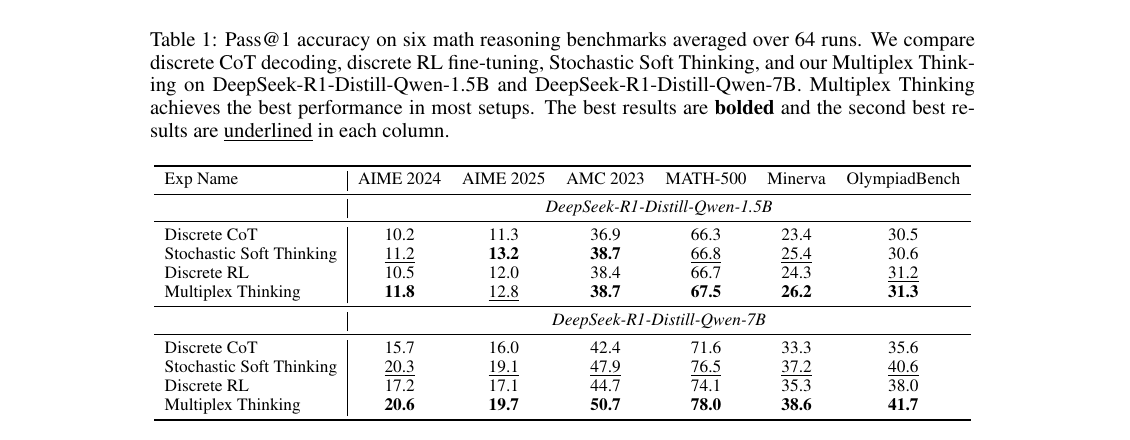
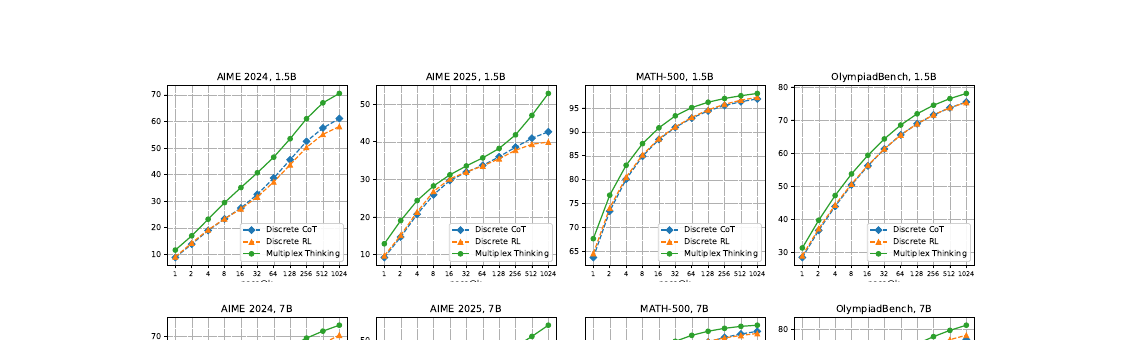
Branch-and-merge unlocks trajectories with negligible discrete probability — the bigger the sample budget, the bigger the advantage.

Continuous reasoning isn't just "as good as text" at fixed compute — it goes further.
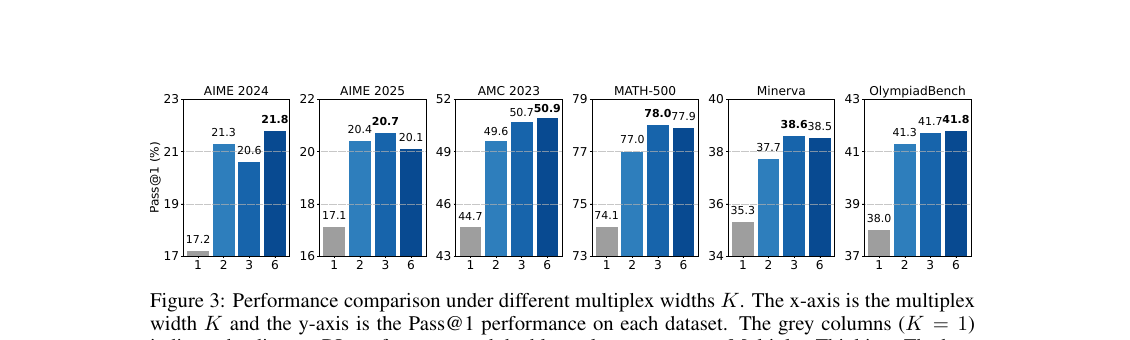
Adaptive without a schedule: the model commits when confident, branches when uncertain — a single K=3 setting handles both regimes.

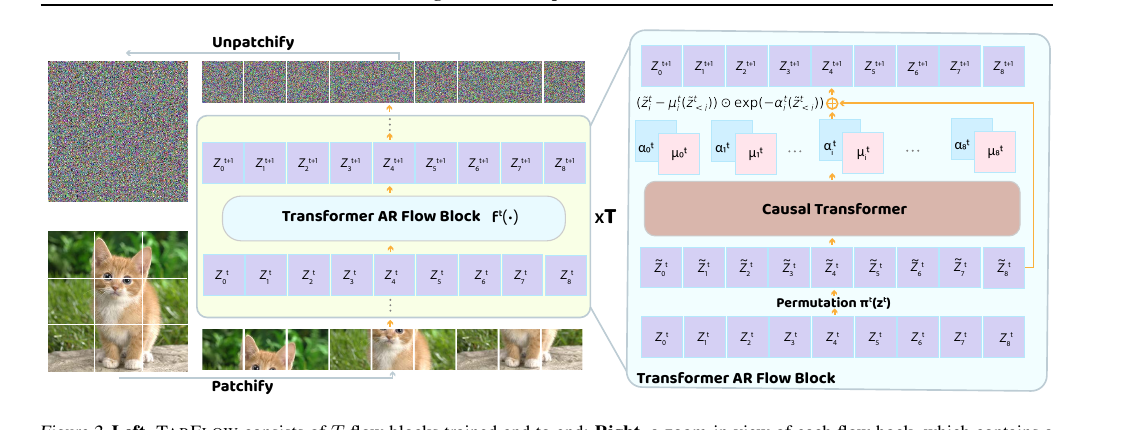
TARFlow showed continuous-image AR flows match diffusion quality from a stand-alone NF.
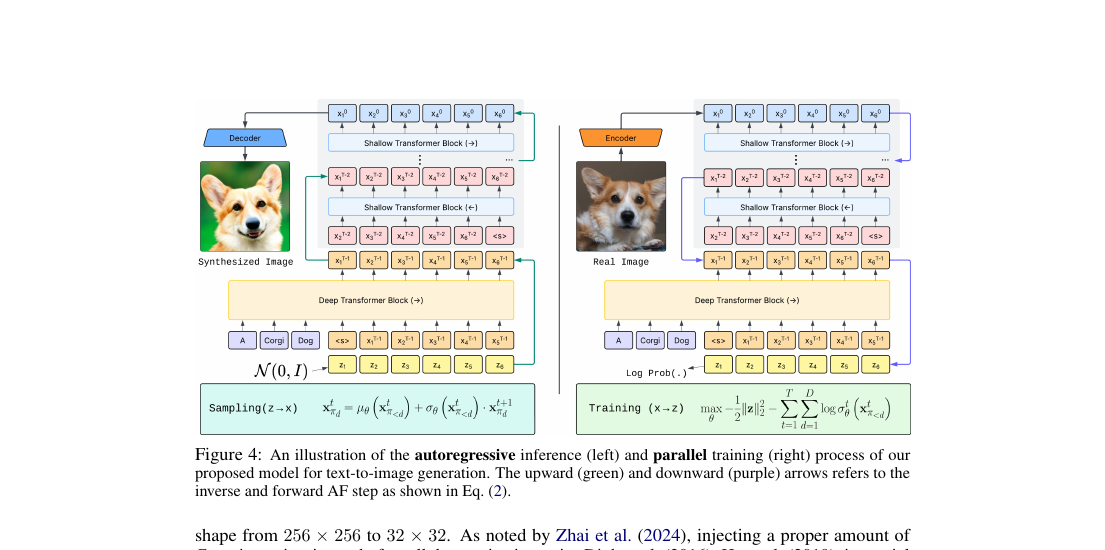
For reasoning we don't need 1024² — but the deep–shallow recipe is what NF-CoT borrows to slot the NF head into a regular LLM.
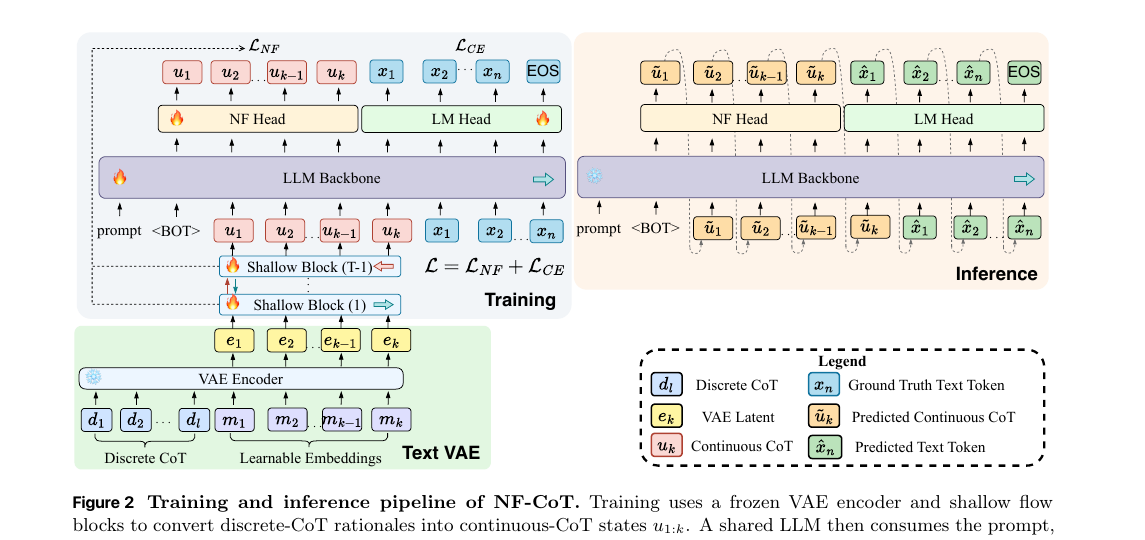
Joint loss: $\mathcal{L} = \lambda_{\text{flow}}\,\mathcal{L}_{\text{flow}} + \lambda_{\text{text}}\,\mathcal{L}_{\text{text}}$ with both $\lambda = 1.0$.
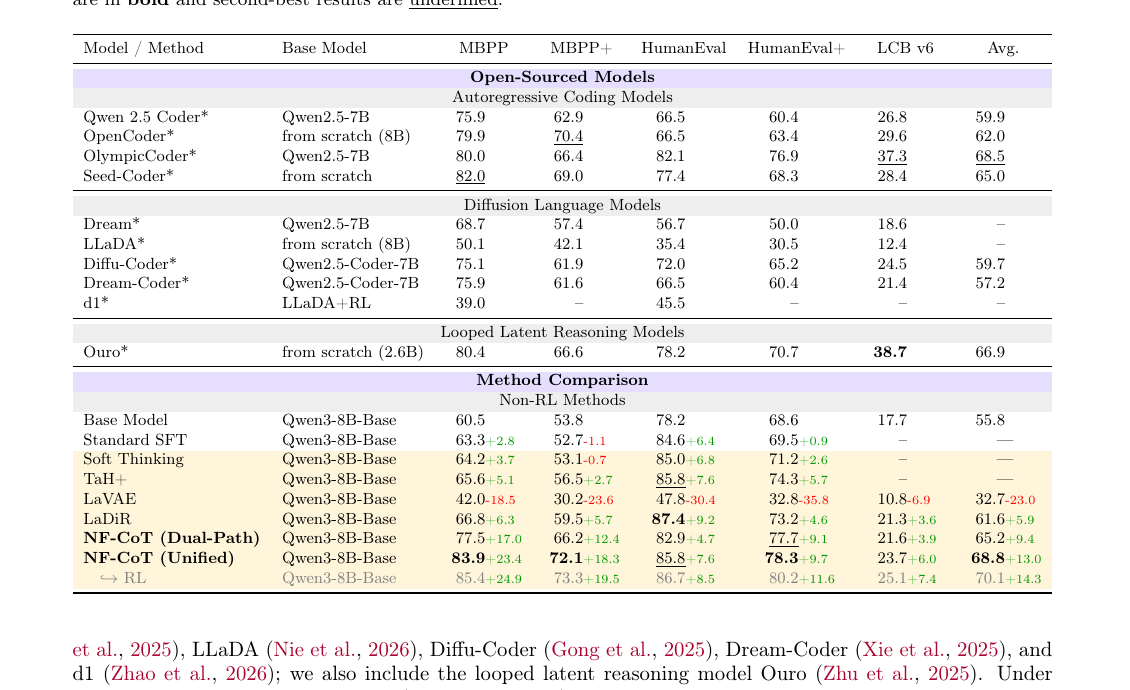
Same 8B backbone for all methods. NF-CoT adds the NF head + 5 shallow flow blocks; rest of LLM is the same.
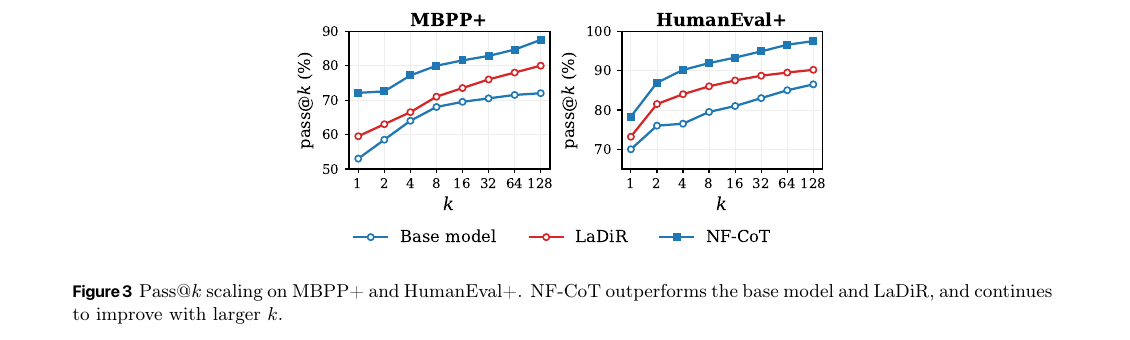
A real density on the trace ⇒ honest exploration ⇒ scaling with sample budget.

Single AR forward pass replaces ~30 denoising steps of LaDiR — exactly what dropping the iterative loop buys.
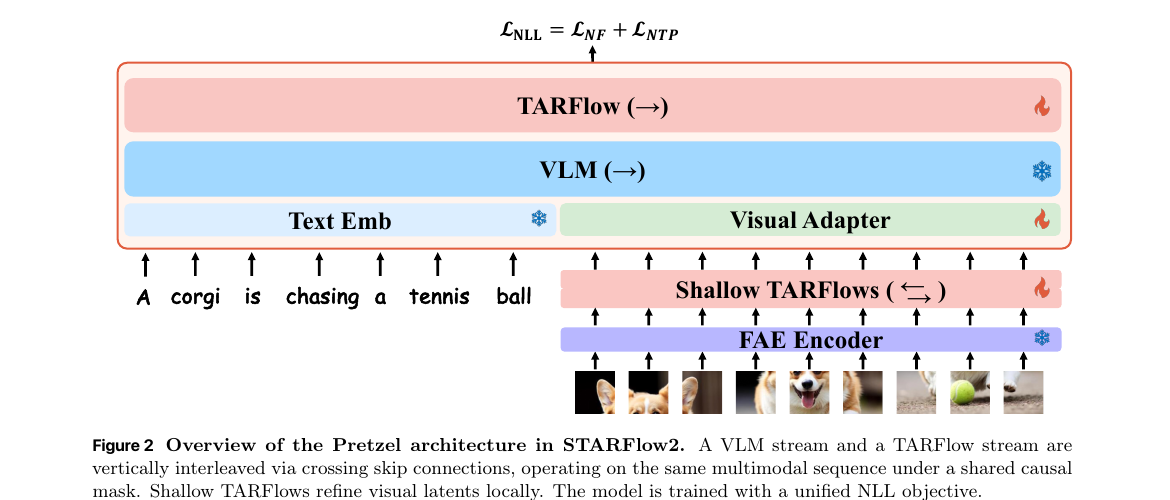
A single causal model that understands, reasons over, and generates continuous images via the same AR mechanism — same mask, same KV-cache, only the output head changes.
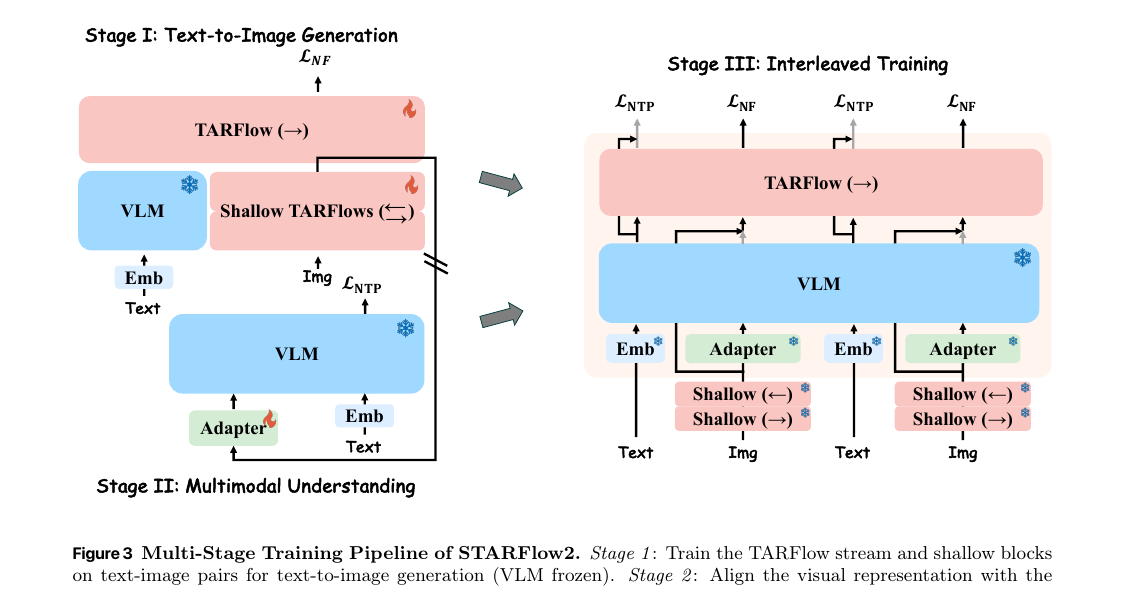
Stage 1 → Stage 3: GenEval 0.51 → 0.82 (+60.8% relative). Joint training doesn't degrade T2I; it improves it.
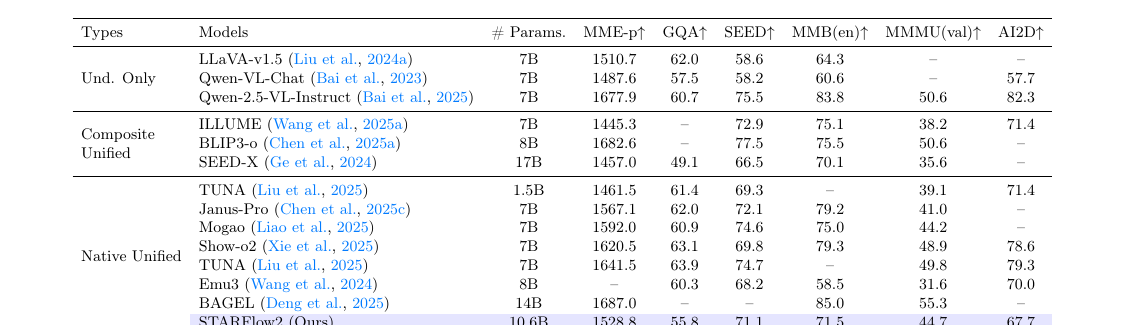
Multimodal understanding (Table 1)
Text-to-image generation (Table 2, GenEval)

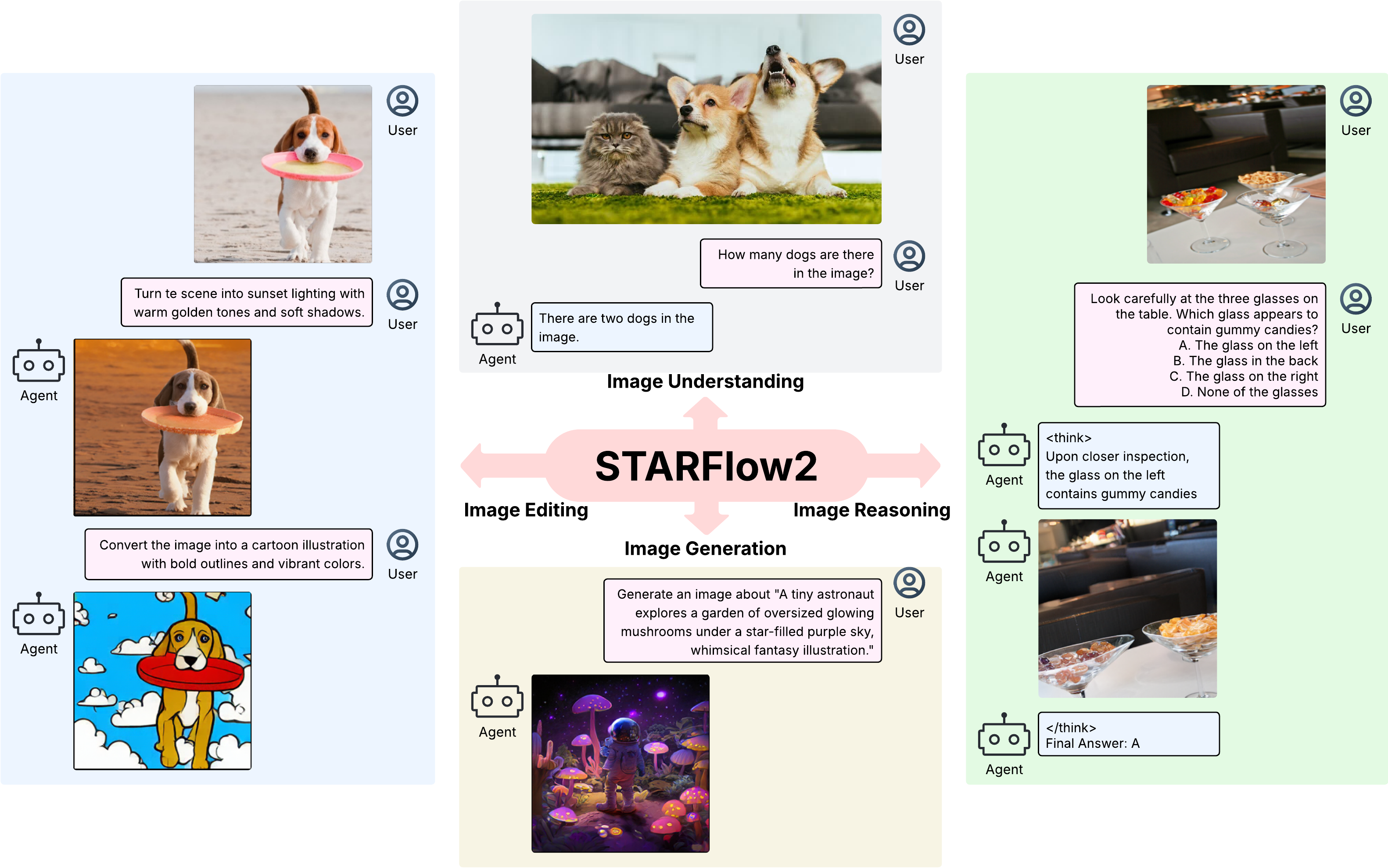
Reasoning that mixes modalities before it is communicated — exactly the "internal-first / partially formed" property we asked for in ds3.
Always recruiting — PhD students, interns, and visiting collaborators. multipath.github.io
Probabilistic continuous reasoning — a real density, end-to-end RL.
Multiplex (Tang et al., arXiv'26) · STARFlow2 (Shen et al., arXiv'26) · TARFlow (ICML'25 Oral) · STARFlow (NeurIPS'25 Spotlight)
NF-CoT (Tu, Fu et al., UPenn / GMLR-Penn) — coming soon
