Selected Publications
You can also find the full list of my publicaiton at Google Scholar Profile.
(* = equal contribution)
2025
-

-
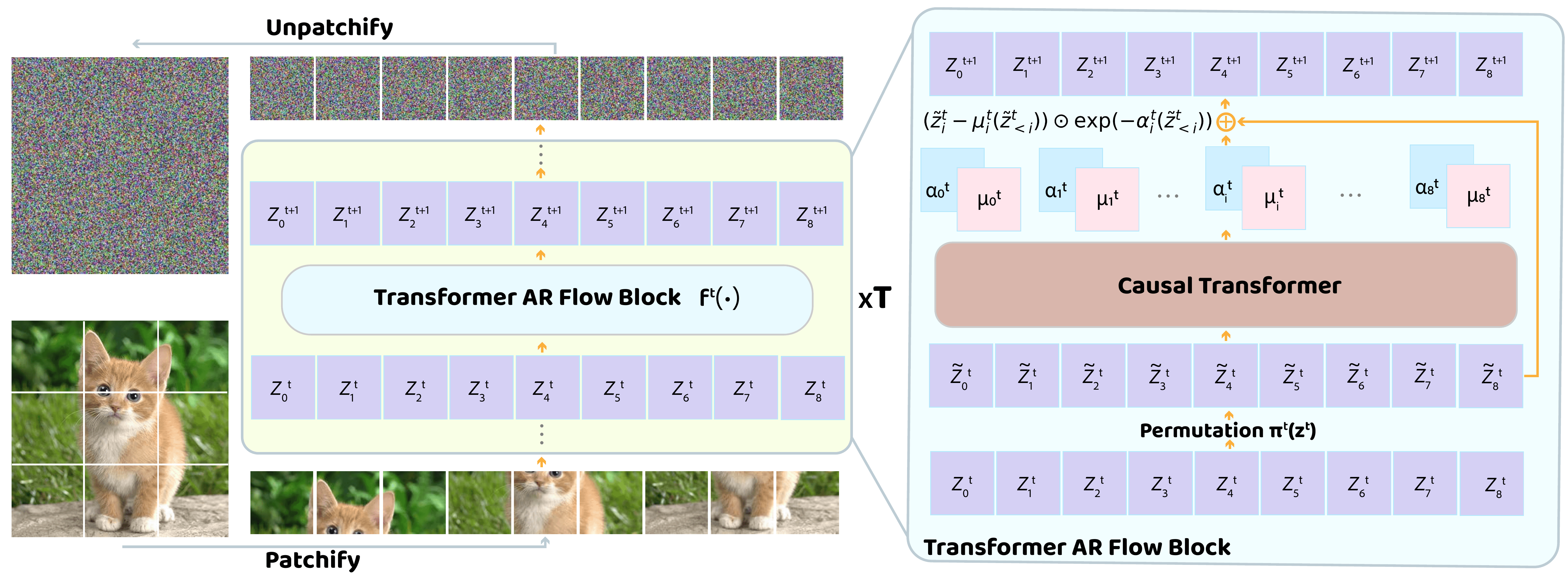
STARFlow: Scaling Latent Normalizing Flows for High-resolution Image Synthesis
, Tianrong Chen, David Berthelot, Huangjie Zheng, Yuyang Wang, Ruixiang Zhang, Laurent Dinh, Miguel Angel Bautista, Josh Susskind, Shuangfei Zhai
NeurIPS 2025 (Spotlight, top 3%)
BIB ABSTRACT
We present STARFlow, a scalable generative model based on normalizing flows that achieves strong performance in high-resolution image synthesis. The core of STARFlow is Transformer Autoregressive Flow (TARFlow), which combines the expressive power of normalizing flows with the structured modeling capabilities of Autoregressive Transformers. We first establish the theoretical universality of TARFlow for modeling continuous distributions. Building on this foundation, we introduce several key architectural and algorithmic innovations to significantly enhance scalability: (1) a deep-shallow design, wherein a deep Transformer block captures most of the model representational capacity, complemented by a few shallow Transformer blocks that are computationally efficient yet substantially beneficial; (2) modeling in the latent space of pretrained autoencoders, which proves more effective than direct pixel-level modeling; and (3) a novel guidance algorithm that significantly boosts sample quality. Crucially, our model remains an end-to-end normalizing flow, enabling exact maximum likelihood training in continuous spaces without discretization. STARFlow achieves competitive performance in both class-conditional and text-conditional image generation tasks, approaching state-of-the-art diffusion models in sample quality. To our knowledge, this work is the first successful demonstration of normalizing flows operating effectively at this scale and resolution.
-
-
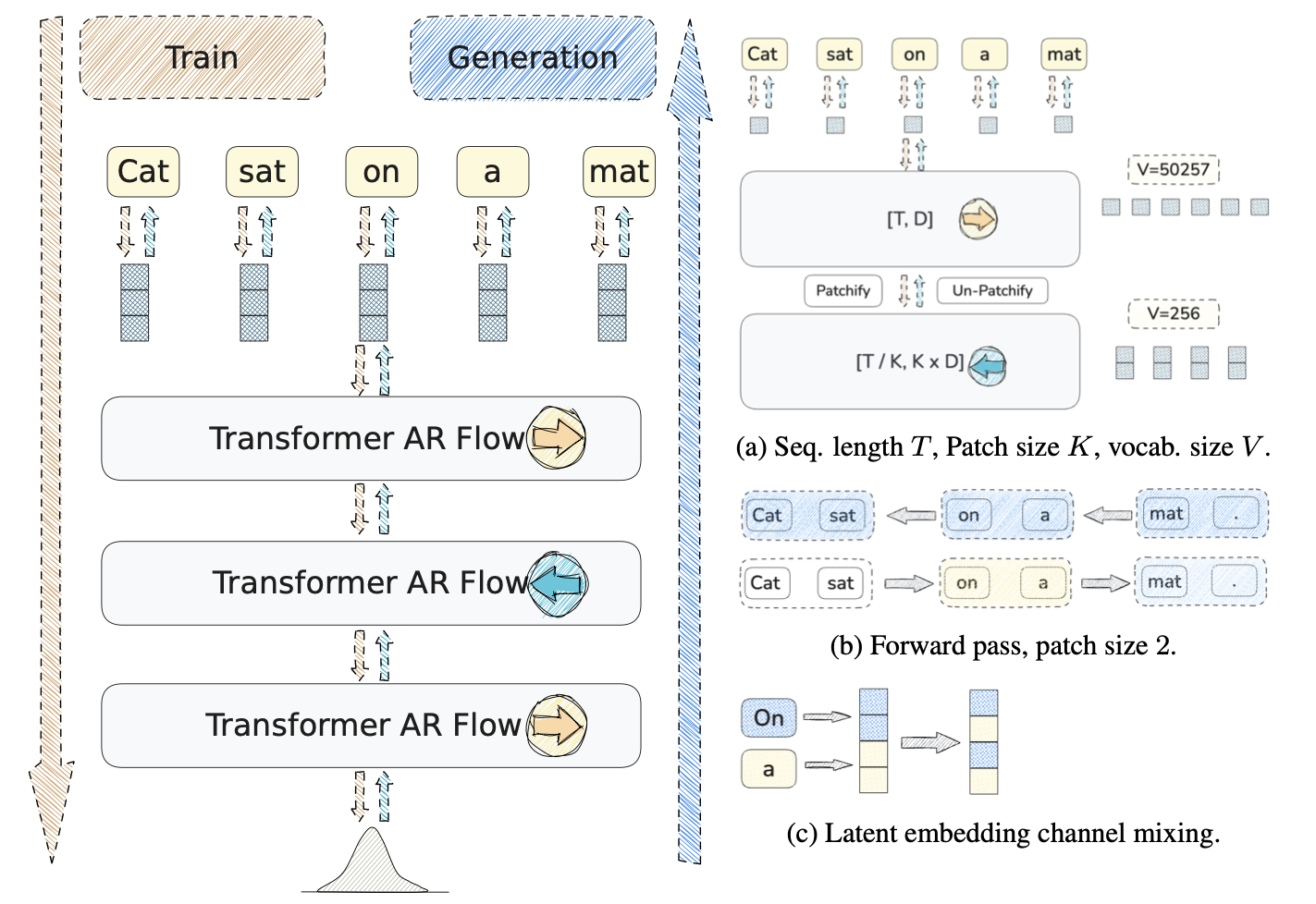
Flexible Language Modeling in Continuous Space with Transformer-based Autoregressive Flows
Ruixiang Zhang, Shuangfei Zhai, , Yizhe Zhang, Huangjie Zheng, Tianrong Chen, Miguel Angel Bautista, Josh Susskind, Navdeep Jaitly
NeurIPS 2025
BIB ABSTRACT
Autoregressive models have driven remarkable progress in language modeling. Their foundational reliance on discrete tokens, unidirectional context, and single-pass decoding, while central to their success, also inspires the exploration of a design space that could offer new axes of modeling flexibility. In this work, we explore an alternative paradigm, shifting language modeling from a discrete token space to a continuous latent space. We propose a novel framework TarFlowLM, that employs transformer-based autoregressive normalizing flows to model these continuous representations. This approach unlocks substantial flexibility, enabling the construction of models that can capture global bi-directional context through stacked, alternating-direction autoregressive transformations, support block-wise generation with flexible token patch sizes, and facilitate a hierarchical multi-pass generation process. We further propose new mixture-based coupling transformations designed to capture complex dependencies within the latent space shaped by discrete data, and demonstrate theoretical connections to conventional discrete autoregressive models. Extensive experiments on language modeling benchmarks demonstrate strong likelihood performance and highlight the flexible modeling capabilities inherent in our framework.
-
-
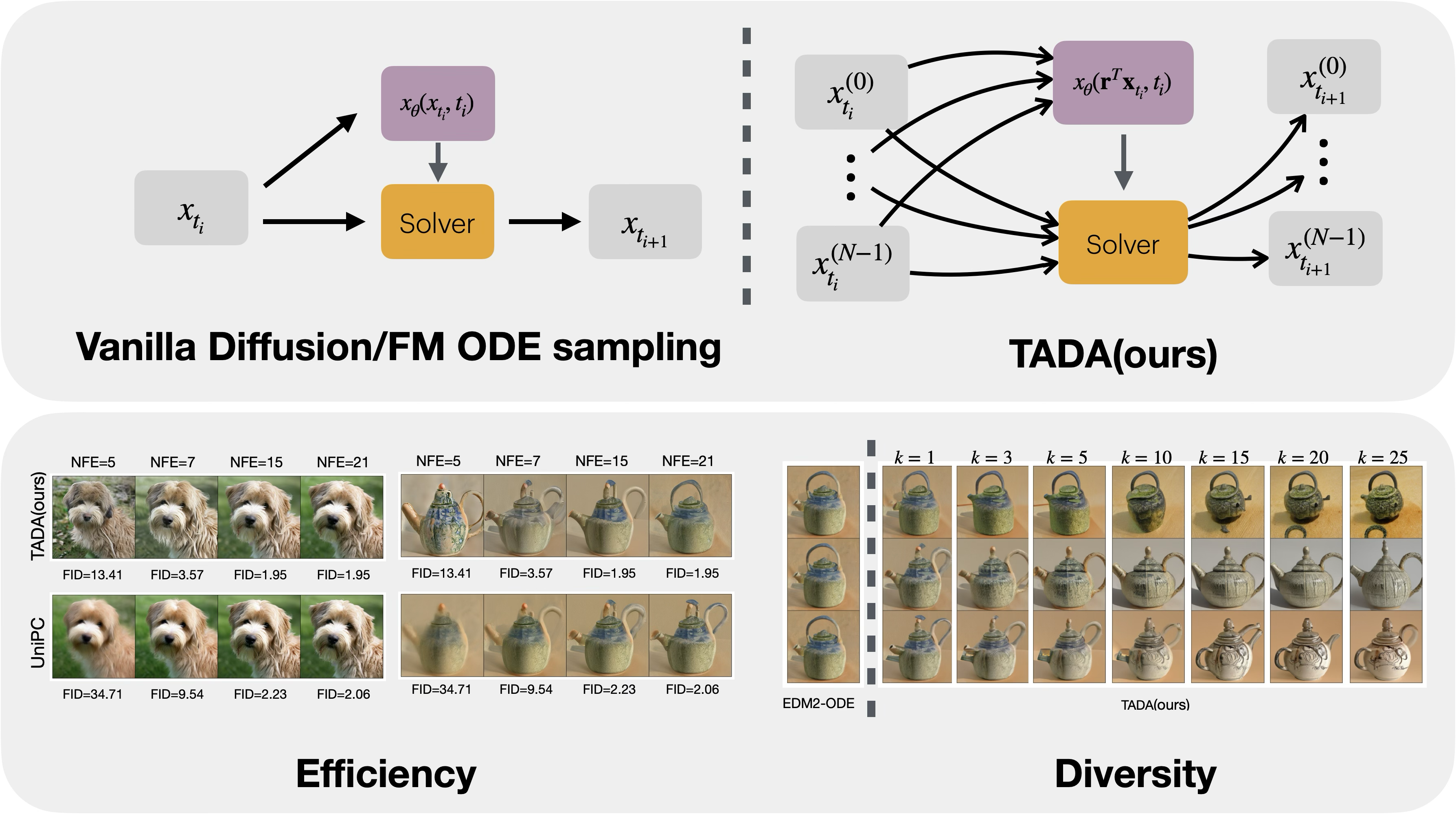
TADA: Improved Diffusion Sampling with Training-free Augmented Dynamics
Tianrong Chen, Huangjie Zheng, David Berthelot, , Josh Susskind, Shuangfei Zhai
NeurIPS 2025
BIB ABSTRACT
Diffusion models have demonstrated exceptional capabilities in generating high-fidelity images but typically suffer from inefficient sampling. Many solver designs and noise scheduling strategies have been proposed to dramatically improve sampling speeds. In this paper, we introduce a new sampling method that is up to $186\%$ faster than the current state of the art solver for comparative FID on ImageNet512. This new sampling method is training-free and uses an ordinary differential equation (ODE) solver. The key to our method resides in using higher-dimensional initial noise, allowing to produce more detailed samples with less function evaluations from existing pretrained diffusion models. In addition, by design our solver allows to control the level of detail through a simple hyper-parameter at no extra computational cost. We present how our approach leverages momentum dynamics by establishing a fundamental equivalence between momentum diffusion models and conventional diffusion models with respect to their training paradigms. Moreover, we observe the use of higher-dimensional noise naturally exhibits characteristics similar to stochastic differential equations (SDEs). Finally, we demonstrate strong performances on a set of representative pretrained diffusion models, including EDM, EDM2, and Stable-Diffusion 3, which cover models in both pixel and latent spaces, as well as class and text conditional settings. The code is available at https://github.com/apple/ml-tada.
-
-
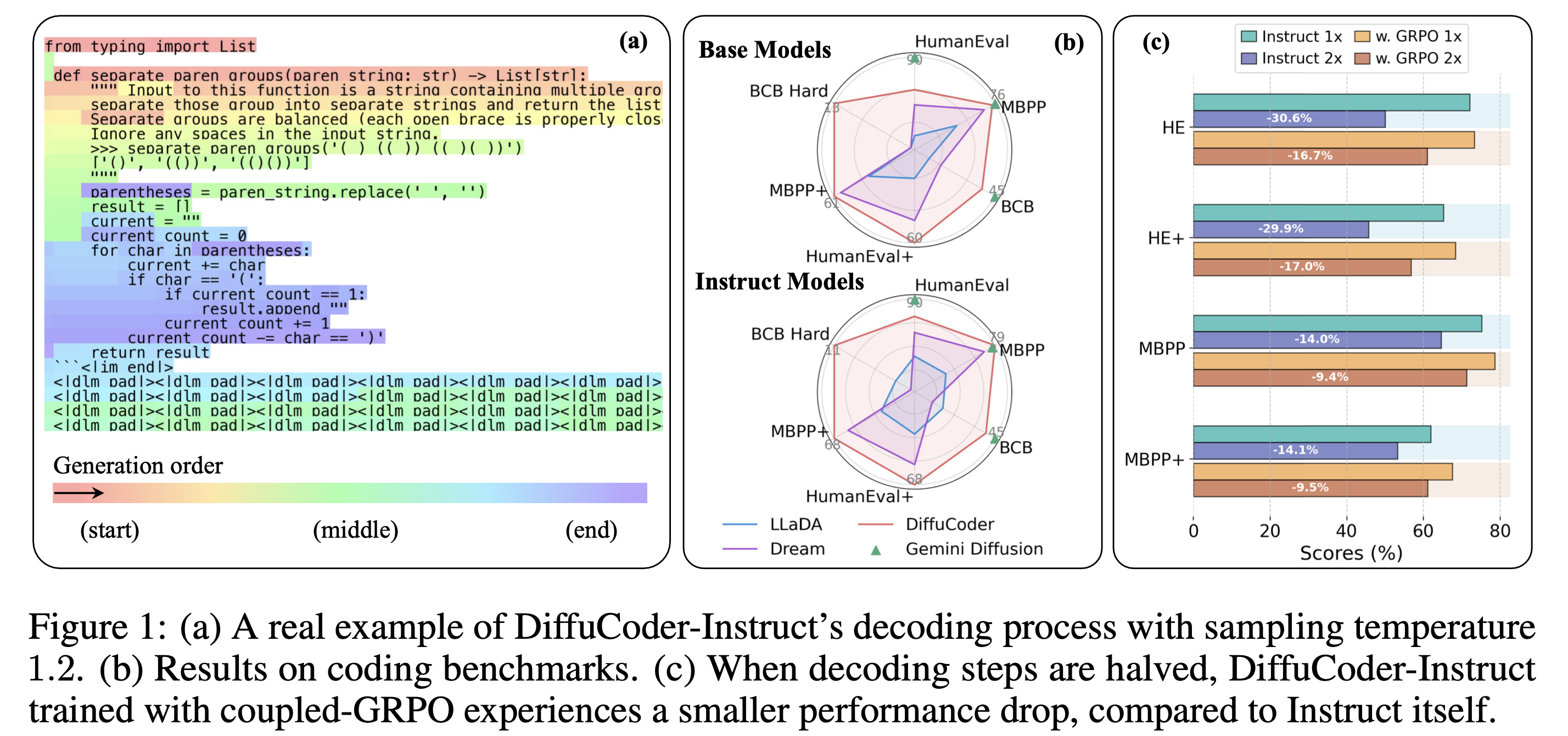
DiffuCoder: Understanding and Improving Masked Diffusion Models for Code Generation
Shansan Gong, Ruixiang Zhang, Huangjie Zheng, , Navdeep Jaitly, Lingpeng Kong, Yizhe Zhang
Arxiv 2025
BIB ABSTRACT
Diffusion large language models (dLLMs) are compelling alternatives to autoregressive (AR) models because their denoising models operate over the entire sequence. The global planning and iterative refinement features of dLLMs are particularly useful for code generation. However, current training and inference mechanisms for dLLMs in coding are still under-explored. To demystify the decoding behavior of dLLMs and unlock their potential for coding, we systematically investigate their denoising processes and reinforcement learning (RL) methods. We train a 7B dLLM, \textbf{DiffuCoder}, on 130B tokens of code. Using this model as a testbed, we analyze its decoding behavior, revealing how it differs from that of AR models: (1) dLLMs can decide how causal their generation should be without relying on semi-AR decoding, and (2) increasing the sampling temperature diversifies not only token choices but also their generation order. This diversity creates a rich search space for RL rollouts. For RL training, to reduce the variance of token log-likelihood estimates and maintain training efficiency, we propose \textbf{coupled-GRPO}, a novel sampling scheme that constructs complementary mask noise for completions used in training. In our experiments, coupled-GRPO significantly improves DiffuCoder's performance on code generation benchmarks (+4.4\% on EvalPlus) and reduces reliance on AR bias during decoding. Our work provides deeper insight into the machinery of dLLM generation and offers an effective, diffusion-native RL training framework. https://github.com/apple/ml-diffucoder.
-
-
Normalizing Flows are Capable Generative Models
Shuangfei Zhai, Ruixiang Zhang, Preetum Nakkiran, David Berthelot, , Huangjie Zheng, Tianrong Chen, Miguel Angel Bautista, Navdeep Jaitly, Josh Susskind
ICML 2025 (Oral, top 1%)
BIB ABSTRACT
Normalizing Flows (NFs) are likelihood-based models for continuous inputs. They have demonstrated promising results on both density estimation and generative modeling tasks, but have received relatively little attention in recent years. In this work, we demonstrate that NFs are more powerful than previously believed. We present TarFlow: a simple and scalable architecture that enables highly performant NF models. TarFlow can be thought of as a Transformer-based variant of Masked Autoregressive Flows (MAFs): it consists of a stack of autoregressive Transformer blocks on image patches, alternating the autoregression direction between layers. TarFlow is straightforward to train end-to-end, and capable of directly modeling and generating pixels. We also propose three key techniques to improve sample quality: Gaussian noise augmentation during training, a post training denoising procedure, and an effective guidance method for both class-conditional and unconditional settings. Putting these together, TarFlow sets new state-of-the-art results on likelihood estimation for images, beating the previous best methods by a large margin, and generates samples with quality and diversity comparable to diffusion models, for the first time with a stand-alone NF model. We make our code available at https://github.com/apple/ml-tarflow.
-
-
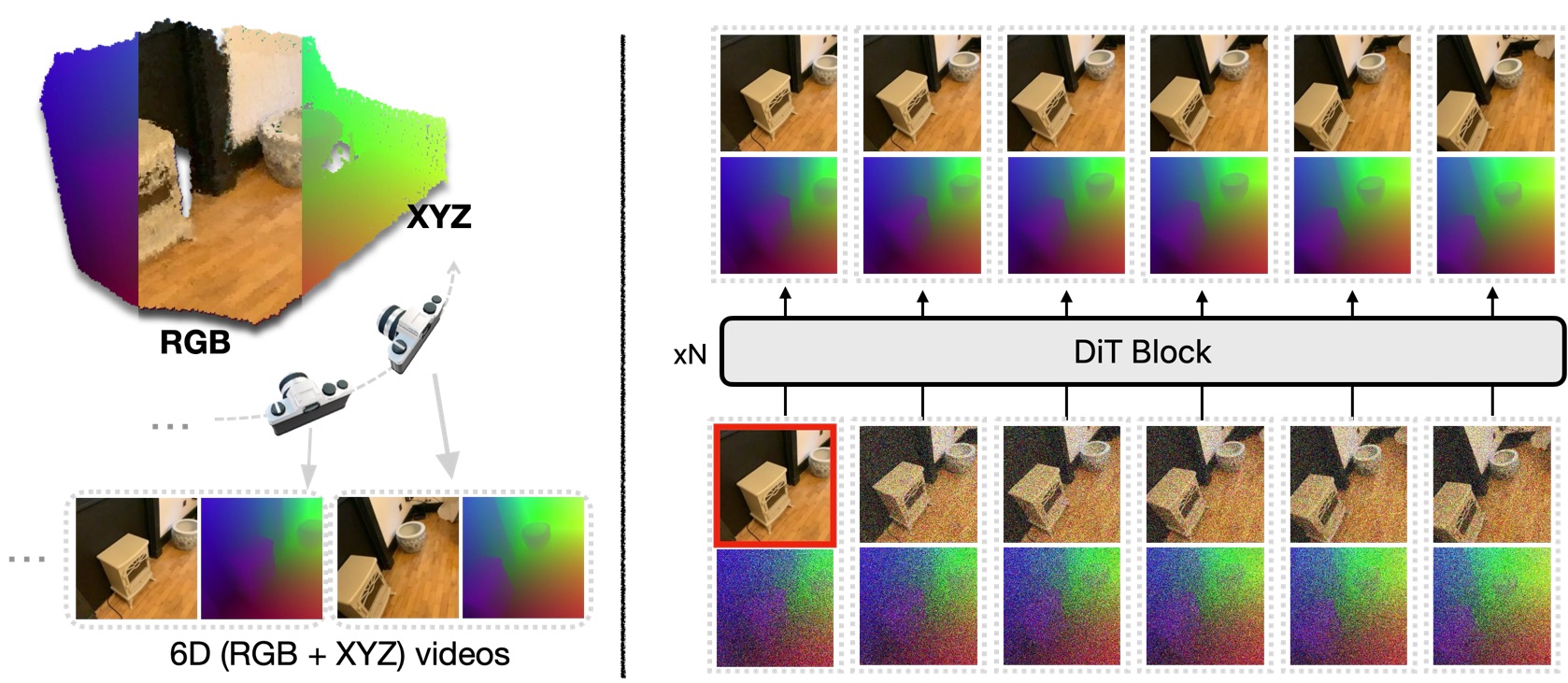
World-consistent Video Diffusion with Explicit 3D Modeling
Qihang Zhang, Shuangfei Zhai, Miguel Angel Bautista, Kevin Miao, Alexander Toshev, Joshua Susskind,
CVPR 2025 (Highlight)
BIB ABSTRACT
Recent advancements in diffusion models have set new benchmarks in image and video generation, enabling realistic visual synthesis across single- and multi-frame contexts. However, these models still struggle with efficiently and explicitly generating 3D-consistent content. To address this, we propose World-consistent Video Diffusion (WVD), a novel framework that incorporates explicit 3D supervision using XYZ images, which encode global 3D coordinates for each image pixel. More specifically, we train a diffusion transformer to learn the joint distribution of RGB and XYZ frames. This approach supports multi-task adaptability via a flexible inpainting strategy. For example, WVD can estimate XYZ frames from ground-truth RGB or generate novel RGB frames using XYZ projections along a specified camera trajectory. In doing so, WVD unifies tasks like single-image-to-3D generation, multi-view stereo, and camera-controlled video generation. Our approach demonstrates competitive performance across multiple benchmarks, providing a scalable solution for 3D-consistent video and image generation with a single pretrained model.
-
-
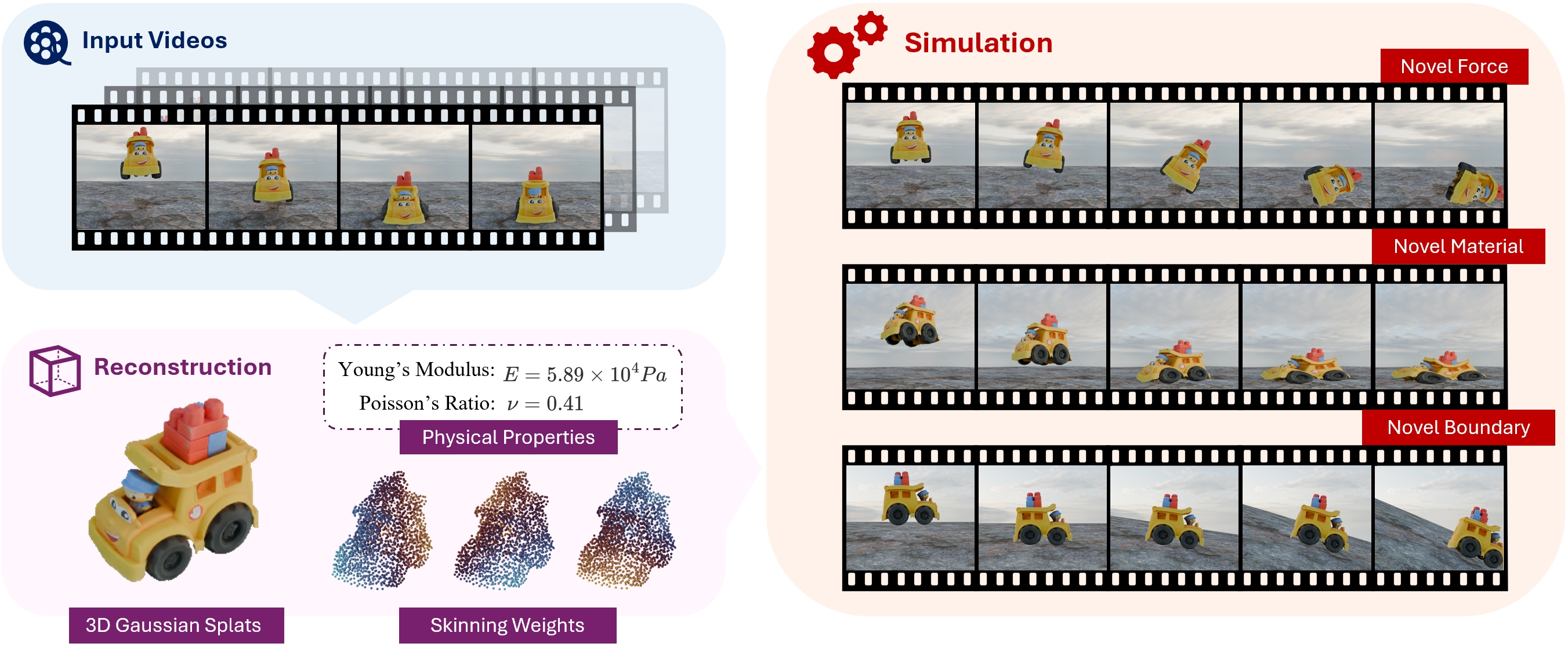
Vid2Sim: Generalizable, Video-based Reconstruction of Appearance, Geometry and Physics for Mesh-free Simulation
Chuhao Chen, Zhiyang Dou, Chen Wang, Yiming Huang, Anjun Chen, Qiao Feng, , Lingjie Liu
CVPR 2025
BIB ABSTRACT
Faithfully reconstructing textured shapes and physical properties from videos presents an intriguing yet challenging problem. Significant efforts have been dedicated to advancing such a system identification problem in this area. Previous methods often rely on heavy optimization pipelines with a differentiable simulator and renderer to estimate physical parameters. However, these approaches frequently necessitate extensive hyperparameter tuning for each scene and involve a costly optimization process, which limits both their practicality and generalizability. In this work, we propose a novel framework, Vid2Sim, a generalizable video-based approach for recovering geometry and physical properties through a mesh-free reduced simulation based on Linear Blend Skinning (LBS), offering high computational efficiency and versatile representation capability. Specifically, Vid2Sim first reconstructs the observed configuration of the physical system from video using a feed-forward neural network trained to capture physical world knowledge. A lightweight optimization pipeline then refines the estimated appearance, geometry, and physical properties to closely align with video observations within just a few minutes. Additionally, after the reconstruction, Vid2Sim enables high-quality, mesh-free simulation with high efficiency. Extensive experiments demonstrate that our method achieves superior accuracy and efficiency in reconstructing geometry and physical properties from video data.
-

-
DART: Denoising autoregressive transformer for scalable text-to-image generation
, Yuyang Wang, Yizhe Zhang, Qihang Zhang, Dinghuai Zhang, Navdeep Jaitly, Josh Susskind, Shuangfei Zhai
ICLR 2025
BIB ABSTRACT
Diffusion models have become the dominant approach for visual generation. They are trained by denoising a Markovian process that gradually adds noise to the input. We argue that the Markovian property limits the models ability to fully utilize the generation trajectory, leading to inefficiencies during training and inference. In this paper, we propose DART, a transformer-based model that unifies autoregressive (AR) and diffusion within a non-Markovian framework. DART iteratively denoises image patches spatially and spectrally using an AR model with the same architecture as standard language models. DART does not rely on image quantization, enabling more effective image modeling while maintaining flexibility. Furthermore, DART seamlessly trains with both text and image data in a unified model. Our approach demonstrates competitive performance on class-conditioned and text-to-image generation tasks, offering a scalable, efficient alternative to traditional diffusion models. Through this unified framework, DART sets a new benchmark for scalable, high-quality image synthesis.
-

-
Improving GFlowNets for Text-to-Image Diffusion Alignment
Dinghuai Zhang, Yizhe Zhang, , Ruixiang Zhang, Josh Susskind, Navdeep Jaitly, Shuangfei Zhai
TMLR
BIB ABSTRACT
Diffusion models have become the \textit{de-facto} approach for generating visual data, which are trained to match the distribution of the training dataset. In addition, we also want to control generation to fulfill desired properties such as alignment to a text description, which can be specified with a black-box reward function. Prior works fine-tune pretrained diffusion models to achieve this goal through reinforcement learning-based algorithms. Nonetheless, they suffer from issues including slow credit assignment as well as low quality in their generated samples. In this work, we explore techniques that do not directly maximize the reward but rather generate high-reward images with relatively high probability -- a natural scenario for the framework of generative flow networks (GFlowNets). To this end, we propose the \textbf{D}iffusion \textbf{A}lignment with \textbf{G}FlowNet (DAG) algorithm to post-train diffusion models with black-box property functions. Extensive experiments on Stable Diffusion and various reward specifications corroborate that our method could effectively align large-scale text-to-image diffusion models with given reward information.
2024
-
-
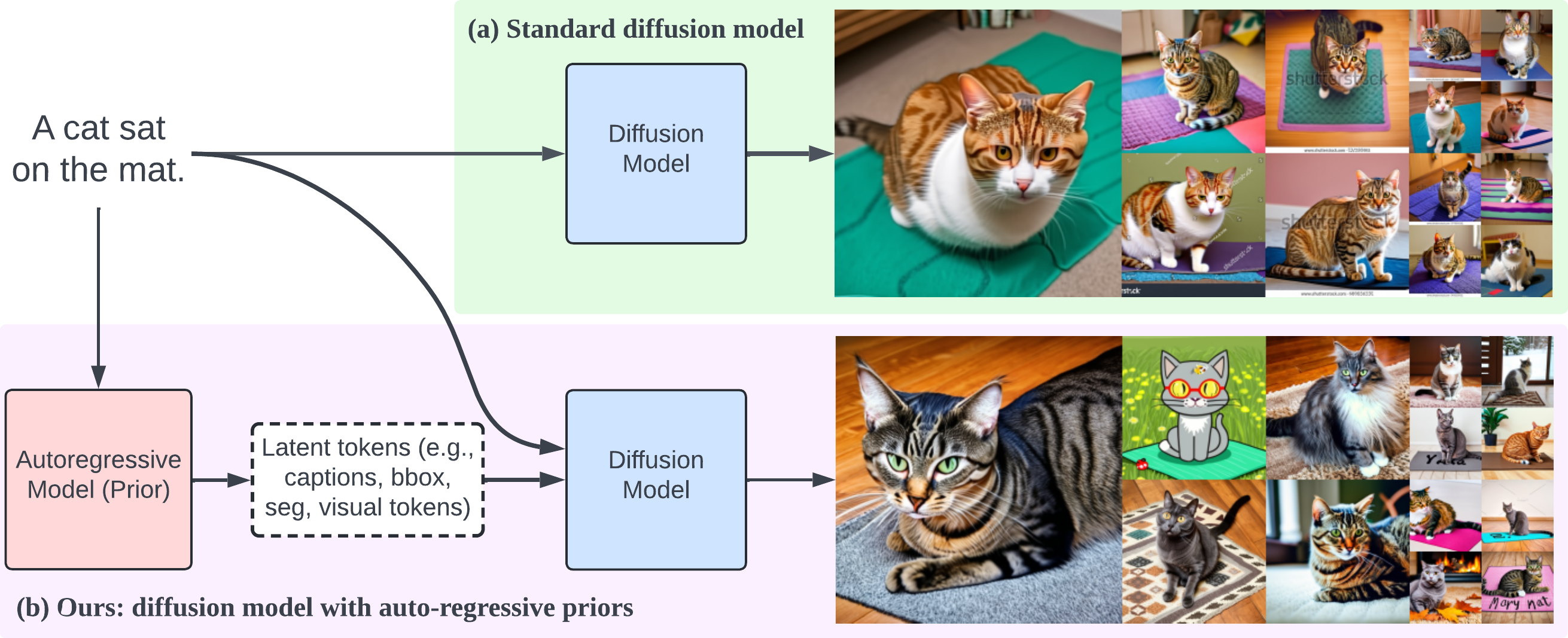
Kaleido Diffusion: Improving Conditional Diffusion Models with Autoregressive Latent Modeling
, Ying Shen, Shuangfei Zhai, Yizhe Zhang, Navdeep Jaitly, Joshua M Susskind
NeurIPS 2024
BIB ABSTRACT
Diffusion models have emerged as a powerful tool for generating high-quality images from textual descriptions. Despite their successes, these models often exhibit limited diversity in the sampled images, particularly when sampling with a high classifier-free guidance weight. To address this issue, we present Kaleido, a novel approach that enhances the diversity of samples by incorporating autoregressive latent priors. Kaleido integrates an autoregressive language model that encodes the original caption and generates latent variables, serving as abstract and intermediary representations for guiding and facilitating the image generation process. In this paper, we explore a variety of discrete latent representations, including textual descriptions, detection bounding boxes, object blobs, and visual tokens. These representations diversify and enrich the input conditions to the diffusion models, enabling more diverse outputs. Our experimental results demonstrate that Kaleido effectively broadens the diversity of the generated image samples from a given textual description while maintaining high image quality. Furthermore, we show that Kaleido adheres closely to the guidance provided by the generated latent variables, demonstrating its capability to effectively control and direct the image generation process.
-
-
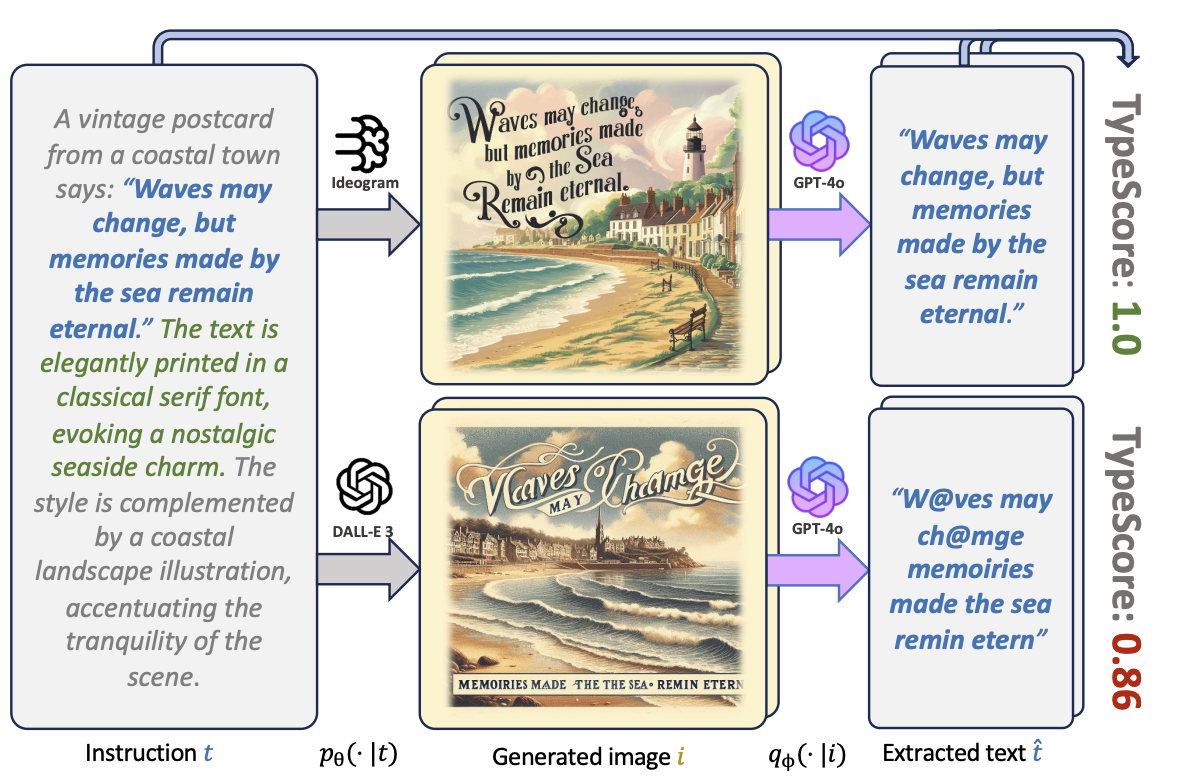
TypeScore: A Text Fidelity Metric for Text-to-Image Generative Models
Georgia Gabriela Sampaio, Ruixiang Zhang, Shuangfei Zhai, , Josh Susskind, Navdeep Jaitly, Yizhe Zhang
Arxiv 2024
BIB ABSTRACT
Evaluating text-to-image generative models remains a challenge, despite the remarkable progress being made in their overall performances. While existing metrics like CLIPScore work for coarse evaluations, they lack the sensitivity to distinguish finer differences as model performance rapidly improves. In this work, we focus on the text rendering aspect of these models, which provides a lens for evaluating a generative model's fine-grained instruction-following capabilities. To this end, we introduce a new evaluation framework called TypeScore to sensitively assess a model's ability to generate images with high-fidelity embedded text by following precise instructions. We argue that this text generation capability serves as a proxy for general instruction-following ability in image synthesis. TypeScore uses an additional image description model and leverages an ensemble dissimilarity measure between the original and extracted text to evaluate the fidelity of the rendered text. Our proposed metric demonstrates greater resolution than CLIPScore to differentiate popular image generation models across a range of instructions with diverse text styles. Our study also evaluates how well these vision-language models (VLMs) adhere to stylistic instructions, disentangling style evaluation from embedded-text fidelity. Through human evaluation studies, we quantitatively meta-evaluate the effectiveness of the metric. Comprehensive analysis is conducted to explore factors such as text length, captioning models, and current progress towards human parity on this task. The framework provides insights into remaining gaps in instruction-following for image generation with embedded text.
-

-
GECO: Generative Image-to-3D within a SECOnd
Chen Wang, , Xiaoxiao Long, Yuan Liu, Lingjie Liu
Arxiv 2024
BIB ABSTRACT
3D generation has seen remarkable progress in recent years. Existing techniques, such as score distillation methods, produce notable results but require extensive per-scene optimization, impacting time efficiency. Alternatively, reconstruction-based approaches prioritize efficiency but compromise quality due to their limited handling of uncertainty. We introduce GECO, a novel method for high-quality 3D generative modeling that operates within a second. Our approach addresses the prevalent issues of uncertainty and inefficiency in current methods through a two-stage approach. In the initial stage, we train a single-step multi-view generative model with score distillation. Then, a second-stage distillation is applied to address the challenge of view inconsistency from the multi-view prediction. This two-stage process ensures a balanced approach to 3D generation, optimizing both quality and efficiency. Our comprehensive experiments demonstrate that GECO achieves high-quality image-to-3D generation with an unprecedented level of efficiency.
-
-
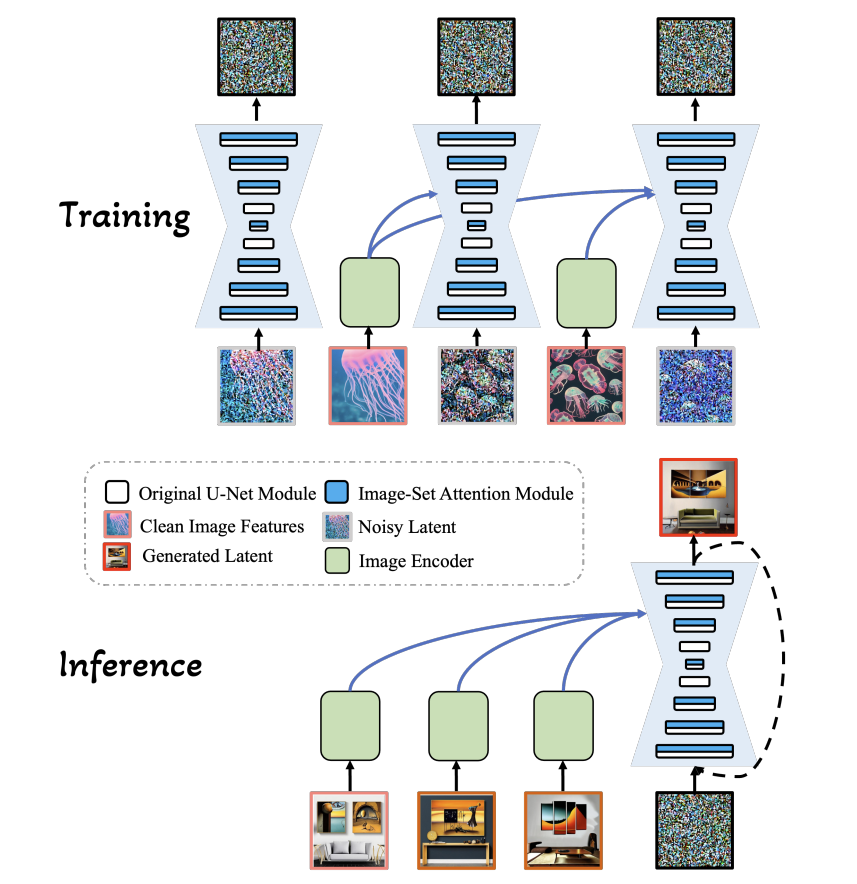
Many-to-many Image Generation with Auto-regressive Diffusion Models
Ying Shen, Yizhe Zhang, Shuangfei Zhai, Lifu Huang, Joshua M Susskind,
Arxiv 2024
BIB ABSTRACT
Recent advancements in image generation have made significant progress, yet existing models present limitations in perceiving and generating an arbitrary number of interrelated images within a broad context. This limitation becomes increasingly critical as the demand for multi-image scenarios, such as multi-view images and visual narratives, grows with the expansion of multimedia platforms. This paper introduces a domain-general framework for many-to-many image generation, capable of producing interrelated image series from a given set of images, offering a scalable solution that obviates the need for task-specific solutions across different multi-image scenarios. To facilitate this, we present MIS, a novel large-scale multi-image dataset, containing 12M synthetic multi-image samples, each with 25 interconnected images. Utilizing Stable Diffusion with varied latent noises, our method produces a set of interconnected images from a single caption. Leveraging MIS, we learn M2M, an autoregressive model for many-to-many generation, where each image is modeled within a diffusion framework. Throughout training on the synthetic MIS, the model excels in capturing style and content from preceding images - synthetic or real - and generates novel images following the captured patterns. Furthermore, through task-specific fine-tuning, our model demonstrates its adaptability to various multi-image generation tasks, including Novel View Synthesis and Visual Procedure Generation.
-
-
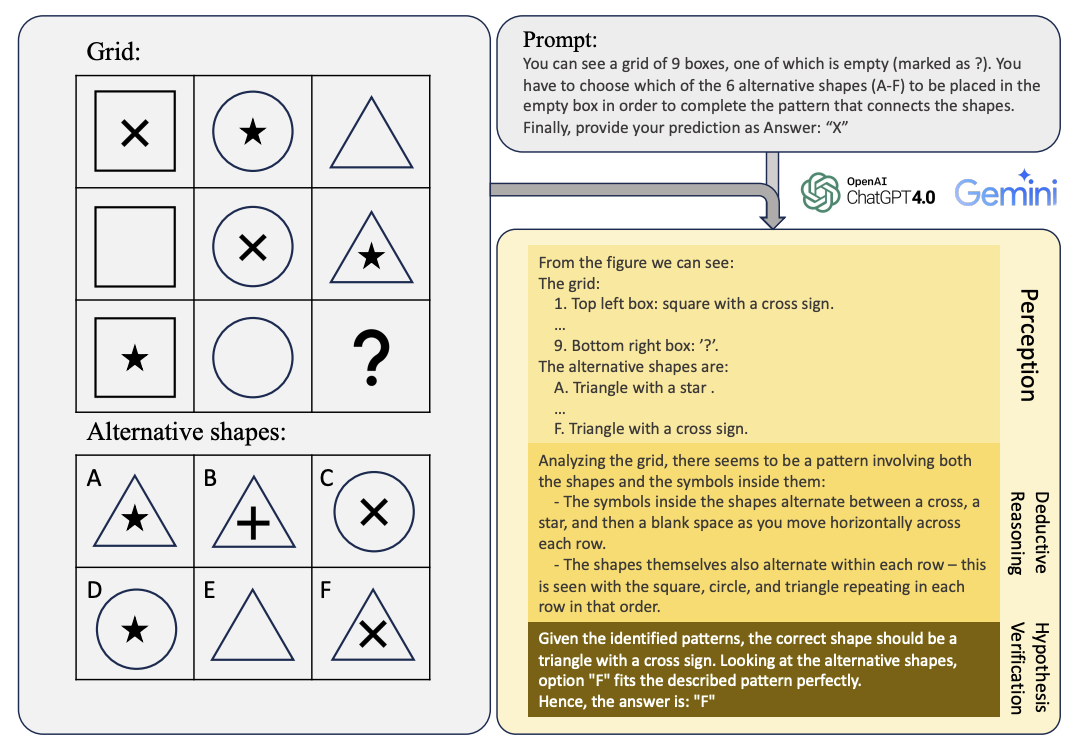
How Far Are We from Intelligent Visual Deductive Reasoning?
Yizhe Zhang, He Bai, Ruixiang Zhang, , Shuangfei Zhai, Josh Susskind, Navdeep Jaitly
COLM 2024
BIB ABSTRACT
Vision-Language Models (VLMs) such as GPT-4V have recently demonstrated incredible strides on diverse vision language tasks. We dig into vision-based deductive reasoning, a more sophisticated but less explored realm, and find previously unexposed blindspots in the current SOTA VLMs. Specifically, we leverage Raven's Progressive Matrices (RPMs), to assess VLMs' abilities to perform multi-hop relational and deductive reasoning relying solely on visual clues. We perform comprehensive evaluations of several popular VLMs employing standard strategies such as in-context learning, self-consistency, and Chain-of-thoughts (CoT) on three diverse datasets, including the Mensa IQ test, IntelligenceTest, and RAVEN. The results reveal that despite the impressive capabilities of LLMs in text-based reasoning, we are still far from achieving comparable proficiency in visual deductive reasoning. We found that certain standard strategies that are effective when applied to LLMs do not seamlessly translate to the challenges presented by visual reasoning tasks. Moreover, a detailed analysis reveals that VLMs struggle to solve these tasks mainly because they are unable to perceive and comprehend multiple, confounding abstract patterns in RPM examples.
-

-
Divide-or-Conquer? Which Part Should You Distill Your LLM?
Zhuofeng Wu, He Bai, Aonan Zhang, , VG Vydiswaran, Navdeep Jaitly, Yizhe Zhang
EMNLP 2024
BIB ABSTRACT
Recent methods have demonstrated that Large Language Models (LLMs) can solve reasoning tasks better when they are encouraged to solve subtasks of the main task first. In this paper we devise a similar strategy that breaks down reasoning tasks into a problem decomposition phase and a problem solving phase and show that the strategy is able to outperform a single stage solution. Further, we hypothesize that the decomposition should be easier to distill into a smaller model compared to the problem solving because the latter requires large amounts of domain knowledge while the former only requires learning general problem solving strategies. We propose methods to distill these two capabilities and evaluate their impact on reasoning outcomes and inference cost. We find that we can distill the problem decomposition phase and at the same time achieve good generalization across tasks, datasets, and models. However, it is harder to distill the problem solving capability without losing performance and the resulting distilled model struggles with generalization. These results indicate that by using smaller, distilled problem decomposition models in combination with problem solving LLMs we can achieve reasoning with cost-efficient inference and local adaptation.
-

-
Diffusion Models Without Attention
Jing Nathan Yan*, *, Alexander M. Rush
CVPR 2024
BIB ABSTRACT
In recent advancements in high-fidelity image generation, Denoising Diffusion Probabilistic Models (DDPMs) have emerged as a key player. However, their application at high resolutions presents significant computational challenges. Current methods, such as patchifying, expedite processes in UNet and Transformer architectures but at the expense of representational capacity. Addressing this, we introduce the Diffusion State Space Model (DiffuSSM), an architecture that supplants attention mechanisms with a more scalable state space model backbone. This approach effectively handles higher resolutions without resorting to global compression, thus preserving detailed image representation throughout the diffusion process. Our focus on FLOP-efficient architectures in diffusion training marks a significant step forward. Comprehensive evaluations on both ImageNet and LSUN datasets at two resolutions demonstrate that DiffuSSMs are on par or even outperform existing diffusion models with attention modules in FID and Inception Score metrics while significantly reducing total FLOP usage.
-

-
Matryoshka Diffusion Models
, Shuangfei Zhai, Yizhe Zhang, Josh Susskind, Navdeep Jaitly
ICLR 2024
BIB ABSTRACT
Diffusion models are the de facto approach for generating high-quality images and videos, but learning high-dimensional models remains a formidable task due to computational and optimization challenges. Existing methods often resort to training cascaded models in pixel space or using a downsampled latent space of a separately trained auto-encoder. In this paper, we introduce Matryoshka Diffusion Models(MDM), an end-to-end framework for high-resolution image and video synthesis. We propose a diffusion process that denoises inputs at multiple resolutions jointly and uses a NestedUNet architecture where features and parameters for small-scale inputs are nested within those of large scales. In addition, MDM enables a progressive training schedule from lower to higher resolutions, which leads to significant improvements in optimization for high-resolution generation. We demonstrate the effectiveness of our approach on various benchmarks, including class-conditioned image generation, high-resolution text-to-image, and text-to-video applications. Remarkably, we can train a single pixel-space model at resolutions of up to 1024x1024 pixels, demonstrating strong zero-shot generalization using the CC12M dataset, which contains only 12 million images.
-

-
Generative Modeling with Phase Stochastic Bridges
Tianrong Chen, , Laurent Dinh, Evangelos A. Theodorou, Josh Susskind, Shuangfei Zhai
ICLR 2024 (Oral)
BIB ABSTRACT
Diffusion models (DMs) represent state-of-the-art generative models for continuous inputs. DMs work by constructing a Stochastic Differential Equation (SDE) in the input space (ie, position space), and using a neural network to reverse it. In this work, we introduce a novel generative modeling framework grounded in \textbf{phase space dynamics}, where a phase space is defined as {an augmented space encompassing both position and velocity.} Leveraging insights from Stochastic Optimal Control, we construct a path measure in the phase space that enables efficient sampling. {In contrast to DMs, our framework demonstrates the capability to generate realistic data points at an early stage of dynamics propagation.} This early prediction sets the stage for efficient data generation by leveraging additional velocity information along the trajectory. On standard image generation benchmarks, our model yields favorable performance over baselines in the regime of small Number of Function Evaluations (NFEs). Furthermore, our approach rivals the performance of diffusion models equipped with efficient sampling techniques, underscoring its potential as a new tool generative modeling.
-
-
BOOT: Data-free Distillation of Denoising Diffusion Models with Bootstrapping
, Shuangfei Zhai, Yizhe Zhang, Lingjie Liu, Josh Susskind
ICML 2024
BIB ABSTRACT
Diffusion models have demonstrated excellent potential for generating diverse images. However, their performance often suffers from slow generation due to iterative denoising. Existing distillation methods either require significant amounts of offline computation for generating synthetic training data or need to perform expensive online learning with the help of real data. In this work, we present a novel technique called BOOT, that overcomes these limitations with an efficient data-free distillation algorithm. The core idea is to learn a time-conditioned model that predicts the output of a pre-trained diffusion model teacher given any time step. Such a model can be efficiently trained based on bootstrapping from two consecutive sampled steps. Furthermore, our method can be easily adapted to large-scale text-to-image diffusion models, which are challenging for conventional methods given the fact that the training sets are often large and difficult to access. We demonstrate the effectiveness of our approach on several benchmarks, achieving comparable generation quality while being orders of magnitude faster than the diffusion teacher. The text-to-image results show that BOOT is able to handle highly complex distributions, shedding light on efficient generative modeling
-
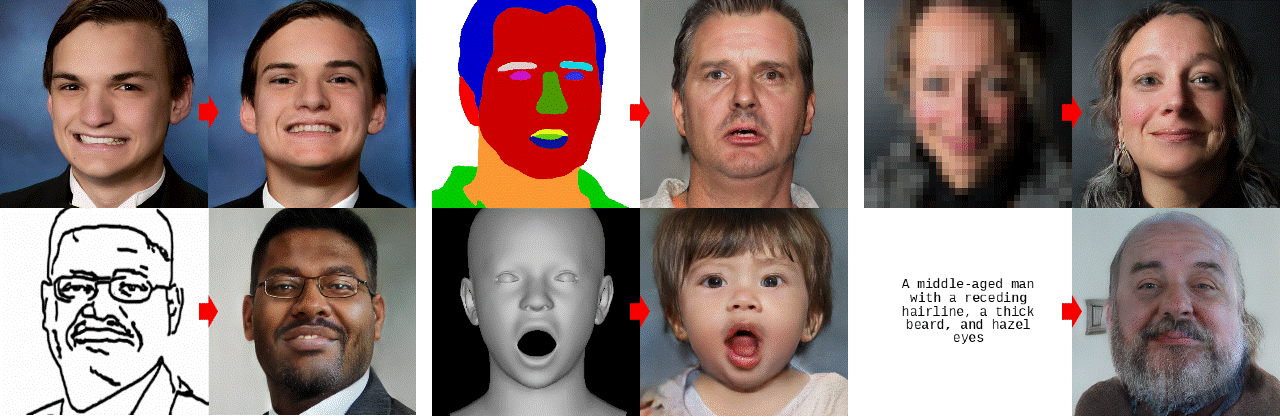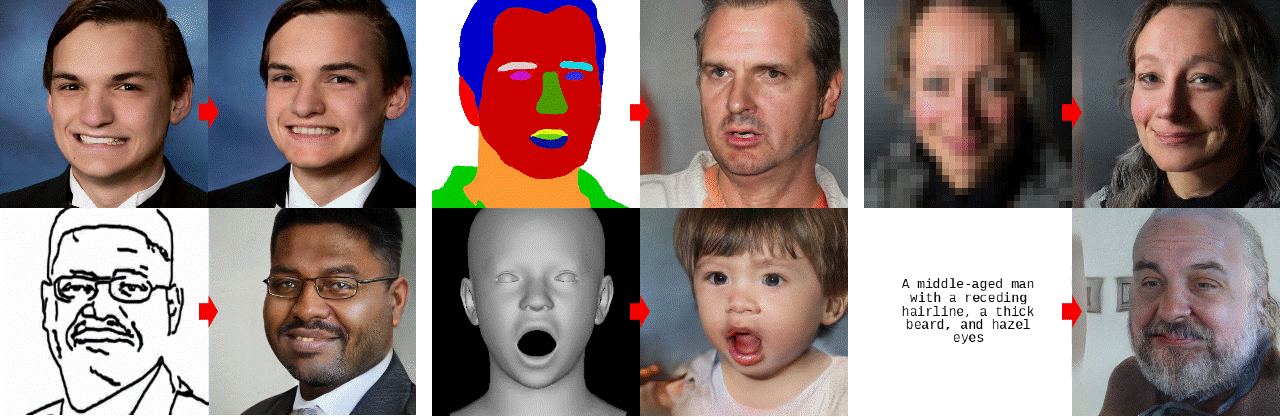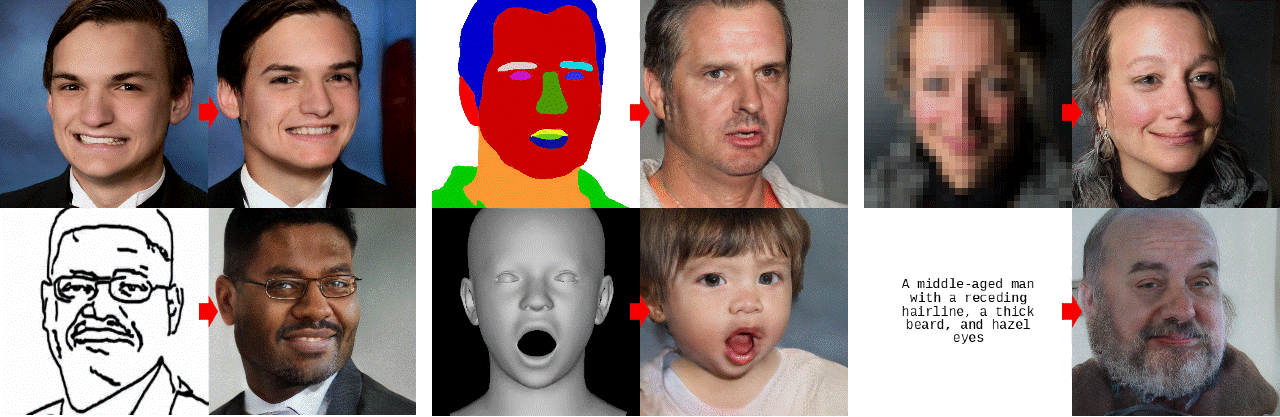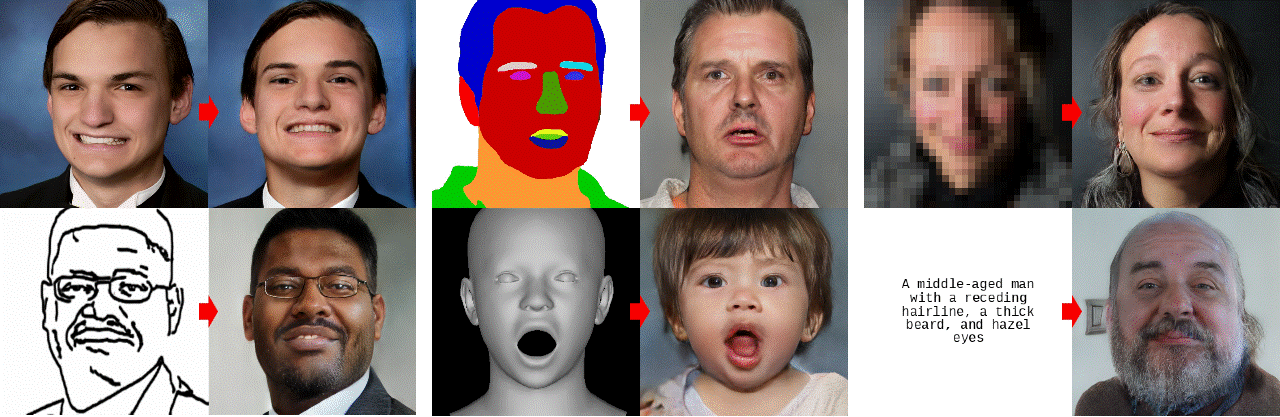
-
Control3Diff: Learning Controllable 3D Diffusion Models from Single-view Images
, Qingzhe Gao, Shuangfei Zhai, Baoquan Chen, Lingjie Liu, Josh Susskind
3DV 2024
BIB ABSTRACT
Diffusion models have recently become the de-facto approach for generative modeling in the 2D domain. However, extending diffusion models to 3D is challenging due to the difficulties in acquiring 3D ground truth data for training. On the other hand, 3D GANs that integrate implicit 3D representations into GANs have shown remarkable 3D-aware generation when trained only on single-view image datasets. However, 3D GANs do not provide straightforward ways to precisely control image synthesis. To address these challenges, We present Control3Diff, a 3D diffusion model that combines the strengths of diffusion models and 3D GANs for versatile, controllable 3D-aware image synthesis for single-view datasets. Control3Diff explicitly models the underlying latent distribution (optionally conditioned on external inputs), thus enabling direct control during the diffusion process. Moreover, our approach is general and applicable to any type of controlling input, allowing us to train it with the same diffusion objective without any auxiliary supervision. We validate the efficacy of Control3Diff on standard image generation benchmarks, including FFHQ, AFHQ, and ShapeNet, using various conditioning inputs such as images, sketches, and text prompts.
2023
-
-
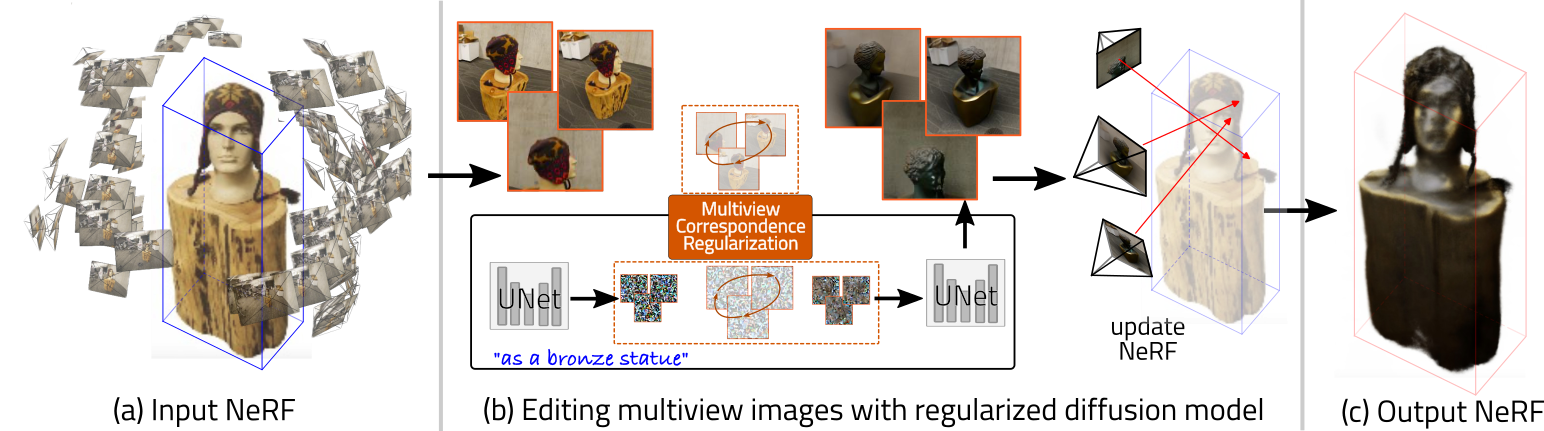
Efficient-NeRF2NeRF: Streamlining Text-Driven 3D Editing with Multiview Correspondence-Enhanced Diffusion Models
Liangchen Song, Liangliang Cao, , Yifan Jiang, Junsong Yuan, Hao Tang
Arxiv 2023
BIB ABSTRACT
The advancement of text-driven 3D content editing has been blessed by the progress from 2D generative diffusion models. However, a major obstacle hindering the widespread adoption of 3D content editing is its time-intensive processing. This challenge arises from the iterative and refining steps required to achieve consistent 3D outputs from 2D image-based generative models. Recent state-of-the-art methods typically require optimization time ranging from tens of minutes to several hours to edit a 3D scene using a single GPU. In this work, we propose that by incorporating correspondence regularization into diffusion models, the process of 3D editing can be significantly accelerated. This approach is inspired by the notion that the estimated samples during diffusion should be multiview-consistent during the diffusion generation process. By leveraging this multiview consistency, we can edit 3D content at a much faster speed. In most scenarios, our proposed technique brings a 10× speed-up compared to the baseline method and completes the editing of a 3D scene in 2 minutes with comparable quality.
-
-
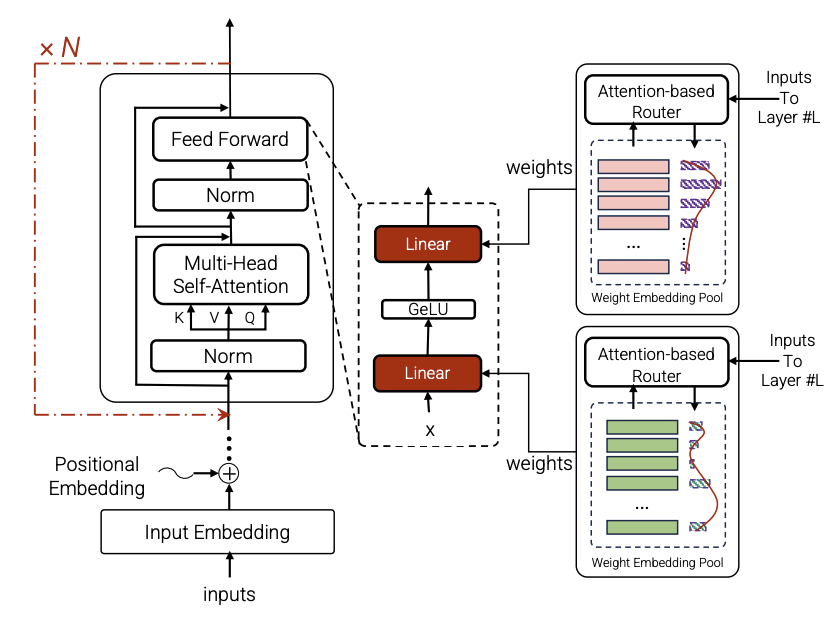
Adaptivity and Modularity for Efficient Generalization Over Task Complexity
Samira Abnar, Omid Saremi, Laurent Dinh, Shantel Wilson, Miguel Angel Bautista, Chen Huang, Vimal Thilak, Etai Littwin, , Josh Susskind, Samy Bengio
Arxiv 2023
BIB ABSTRACT
Can transformers generalize efficiently on problems that require dealing with examples with different levels of difficulty? We introduce a new task tailored to assess generalization over different complexities and present results that indicate that standard transformers face challenges in solving these tasks. These tasks are variations of pointer value retrieval previously introduced by Zhang et al. (2021). We investigate how the use of a mechanism for adaptive and modular computation in transformers facilitates the learning of tasks that demand generalization over the number of sequential computation steps (i.e., the depth of the computation graph). Based on our observations, we propose a transformer-based architecture called Hyper-UT, which combines dynamic function generation from hyper networks with adaptive depth from Universal Transformers. This model demonstrates higher accuracy and a fairer allocation of computational resources when generalizing to higher numbers of computation steps. We conclude that mechanisms for adaptive depth and modularity complement each other in improving efficient generalization concerning example complexity. Additionally, to emphasize the broad applicability of our findings, we illustrate that in a standard image recognition task, Hyper-UT matches that of a ViT model but with considerably reduced computational demands (achieving over 70\% average savings by effectively using fewer layers).
-
-
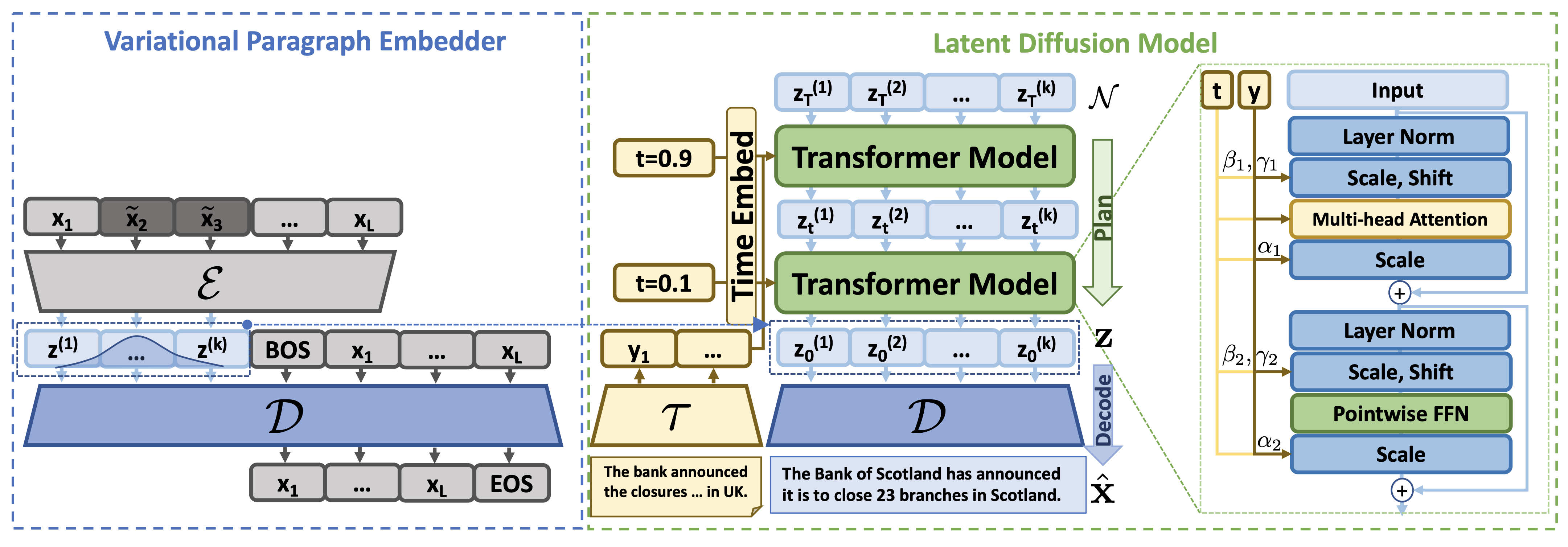
PLANNER: Generating Diversified Paragraph via Latent Language Diffusion Model
Yizhe Zhang, , Zhuofeng Wu, Shuangfei Zhai, Josh Susskind, Navdeep Jaitly
NeurIPS 2023
BIB ABSTRACT
Autoregressive models for text sometimes generate repetitive and low-quality output because errors accumulate during the steps of generation. This issue is often attributed to exposure bias - the difference between how a model is trained, and how it is used during inference. Denoising diffusion models provide an alternative approach in which a model can revisit and revise its output. However, they can be computationally expensive and prior efforts on text have led to models that produce less fluent output compared to autoregressive models, especially for longer text and paragraphs. In this paper, we propose PLANNER, a model that combines latent semantic diffusion with autoregressive generation, to generate fluent text while exercising global control over paragraphs. The model achieves this by combining an autoregressive "decoding" module with a "planning" module that uses latent diffusion to generate semantic paragraph embeddings in a coarse-to-fine manner. The proposed method is evaluated on various conditional generation tasks, and results on semantic generation, text completion and summarization show its effectiveness in generating high-quality long-form text in an efficient manner.
-
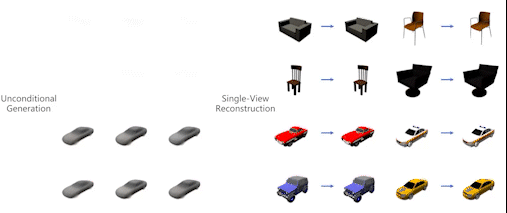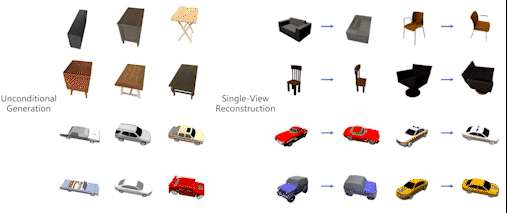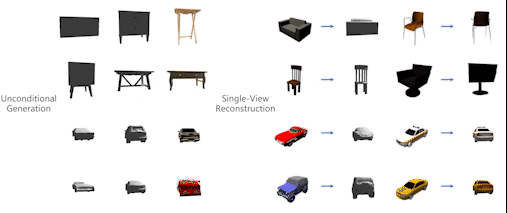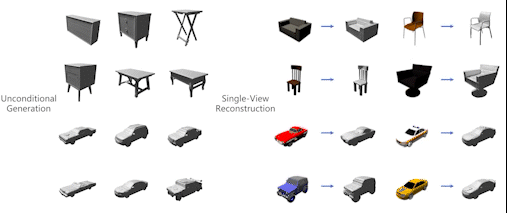
-
Single-Stage Diffusion NeRF: A Unified Approach to 3D Generation and Reconstruction
Hansheng Chen, , Anpei Chen, Wei Tian, Zhuowen Tu, Lingjie Liu, Hao Su
ICCV 2023
BIB ABSTRACT
3D-aware image synthesis encompasses a variety of tasks, such as scene generation and novel view synthesis from images. Despite numerous task-specific methods, developing a comprehensive model remains challenging. In this paper, we present SSDNeRF, a unified approach that employs an expressive diffusion model to learn a generalizable prior of neural radiance fields (NeRF) from multi-view images of diverse objects. Previous studies have used two-stage approaches that rely on pretrained NeRFs as real data to train diffusion models. In contrast, we propose a new single-stage training paradigm with an end-to-end objective that jointly optimizes a NeRF auto-decoder and a latent diffusion model, enabling simultaneous 3D reconstruction and prior learning, even from sparsely available views. At test time, we can directly sample the diffusion prior for unconditional generation, or combine it with arbitrary observations of unseen objects for NeRF reconstruction. SSDNeRF demonstrates robust results comparable to or better than leading task-specific methods in unconditional generation and single/sparse-view 3D reconstruction.
-

-
Nerfdiff: Single-image view synthesis with nerf-guided distillation from 3d-aware diffusion
, Alex Trevithick, Kai-En Lin, Josh Susskind, Christian Theobalt, Lingjie Liu, Ravi Ramamoorthi
ICML 2023
BIB ABSTRACT
Novel view synthesis from a single image requires inferring occluded regions of objects and scenes whilst simultaneously maintaining semantic and physical consistency with the input. Existing approaches condition neural radiance fields (NeRF) on local image features, projecting points to the input image plane, and aggregating 2D features to perform volume rendering. However, under severe occlusion, this projection fails to resolve uncertainty, resulting in blurry renderings that lack details. In this work, we propose NerfDiff, which addresses this issue by distilling the knowledge of a 3D-aware conditional diffusion model (CDM) into NeRF through synthesizing and refining a set of virtual views at test time. We further propose a novel NeRF-guided distillation algorithm that simultaneously generates 3D consistent virtual views from the CDM samples, and finetunes the NeRF based on the improved virtual views. Our approach significantly outperforms existing NeRF-based and geometry-free approaches on challenging datasets, including ShapeNet, ABO, and Clevr3D.
-
-
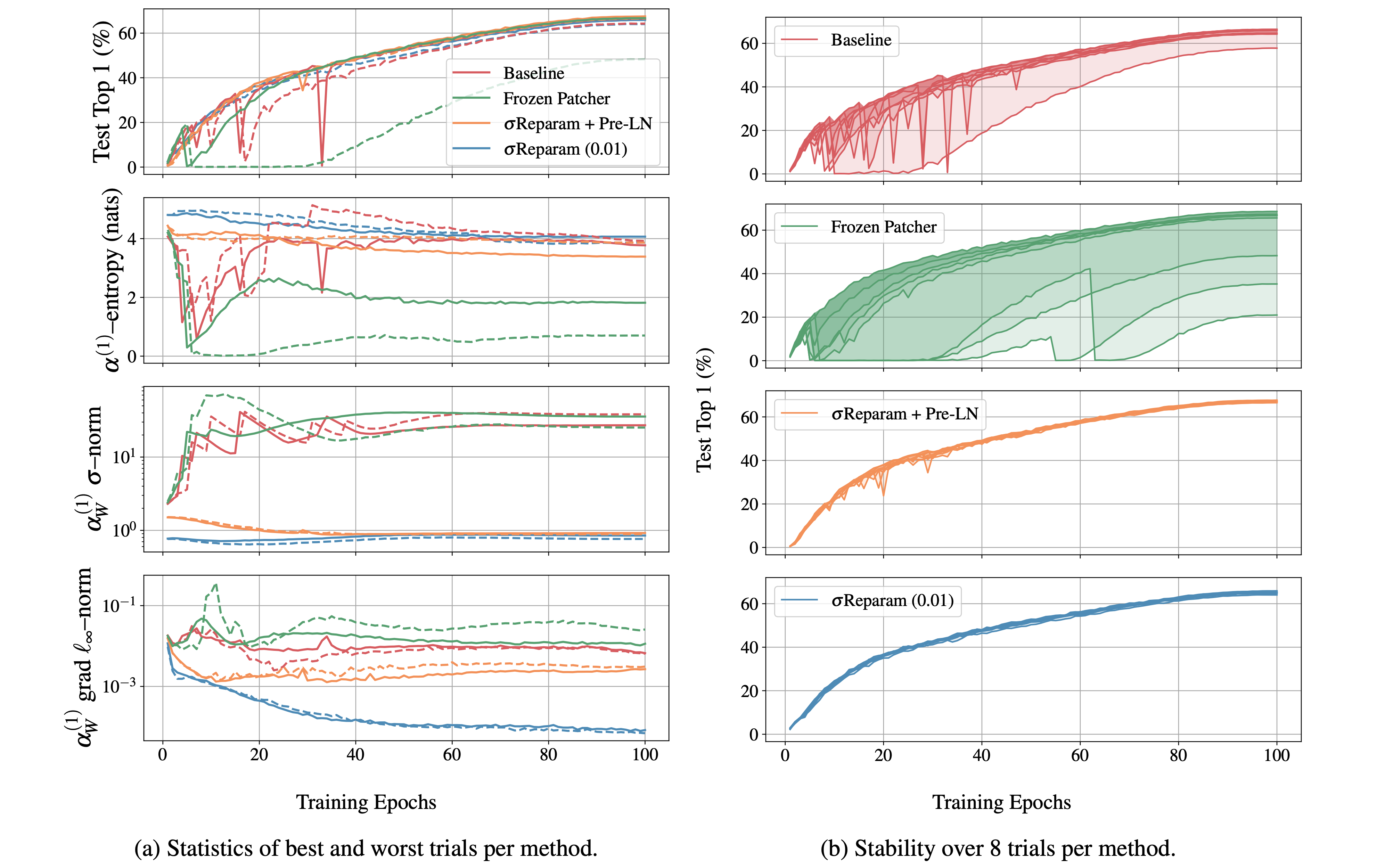
Stabilizing Transformer Training by Preventing Attention Entropy Collapse
Shuangfei Zhai, Tatiana Likhomanenko, Etai Littwin, Dan Busbridge, Jason Ramapuram, Yizhe Zhang, , Josh Susskind
ICML 2023
BIB ABSTRACT
Training stability is of great importance to Transformers. In this work, we investigate the training dynamics of Transformers by examining the evolution of the attention layers. In particular, we track the attention entropy for each attention head during the course of training, which is a proxy for model sharpness. We identify a common pattern across different architectures and tasks, where low attention entropy is accompanied by high training instability, which can take the form of oscillating loss or divergence. We denote the pathologically low attention entropy, corresponding to highly concentrated attention scores, as entropy collapse. As a remedy, we propose σReparam, a simple and efficient solution where we reparametrize all linear layers with spectral normalization and an additional learned scalar. We demonstrate that the proposed reparameterization successfully prevents entropy collapse in the attention layers, promoting more stable training. Additionally, we prove a tight lower bound of the attention entropy, which decreases exponentially fast with the spectral norm of the attention logits, providing additional motivation for our approach. We conduct experiments with σReparam on image classification, image self-supervised learning, machine translation, automatic speech recognition, and language modeling tasks, across Transformer architectures. We show that σReparam provides stability and robustness with respect to the choice of hyperparameters, going so far as enabling training (a) a Vision Transformer to competitive performance without warmup, weight decay, layer normalization or adaptive optimizers; (b) deep architectures in machine translation and (c) speech recognition to competitive performance without warmup and adaptive optimizers.
-
-
f-DM: A Multi-stage Diffusion Model via Progressive Signal Transformation
, Shuangfei Zhai, Yizhe Zhang, Miguel Angel Bautista, Josh Susskind
ICLR 2023
BIB ABSTRACT
Diffusion models (DMs) have recently emerged as SoTA tools for generative modeling in various domains. Standard DMs can be viewed as an instantiation of hierarchical variational autoencoders (VAEs) where the latent variables are inferred from input-centered Gaussian distributions with fixed scales and variances. Unlike VAEs, this formulation limits DMs from changing the latent spaces and learning abstract representations. In this work, we propose f-DM, a generalized family of DMs which allows progressive signal transformation. More precisely, we extend DMs to incorporate a set of (hand-designed or learned) transformations, where the transformed input is the mean of each diffusion step. We propose a generalized formulation and derive the corresponding de-noising objective with a modified sampling algorithm. As a demonstration, we apply f-DM in image generation tasks with a range of functions, including down-sampling, blurring, and learned transformations based on the encoder of pretrained VAEs. In addition, we identify the importance of adjusting the noise levels whenever the signal is sub-sampled and propose a simple rescaling recipe. f-DM can produce high-quality samples on standard image generation benchmarks like FFHQ, AFHQ, LSUN, and ImageNet with better efficiency and semantic interpretation.
-

-
Diffusion probabilistic fields
Peiye Zhuang, Samira Abnar, , Alex Schwing, Joshua M Susskind, Miguel Ángel Bautista
ICLR 2023
BIB ABSTRACT
Diffusion probabilistic models have quickly become a major approach for generative modeling of images, 3D geometry, video and other domains. However, to adapt diffusion generative modeling to these domains the denoising network needs to be carefully designed for each domain independently, oftentimes under the assumption that data lives in an Euclidean grid. In this paper we introduce Diffusion Probabilistic Fields (DPF), a diffusion model that can learn distributions over continuous functions defined over metric spaces, commonly known as fields. We extend the formulation of diffusion probabilistic models to deal with this field parametrization in an explicit way, enabling us to define and end-to-end learning algorithm that side-steps the requirement of representing fields with latent vectors as in previous approaches. We empirically show that, while using the same denoising network, DPF effectively deals with different modalities like 2D images and 3D geometry, in addition to modeling distributions over fields defined on non-Euclidean metric spaces.
-
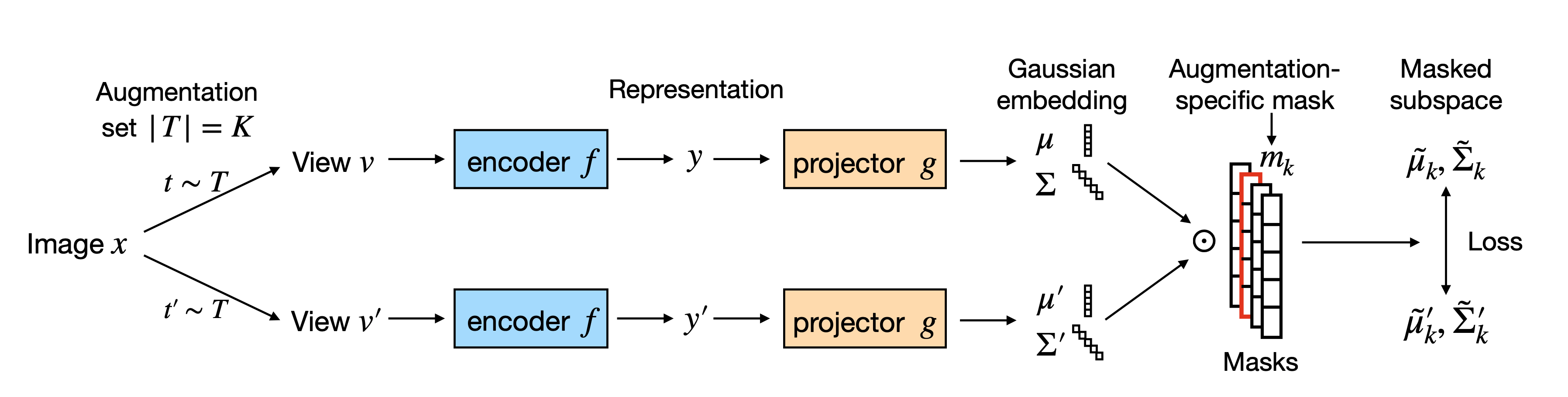
-
MAST: Masked Augmentation Subspace Training for Generalizable Self-Supervised Priorse
Chen Huang, Hanlin Goh, , Josh Susskind
ICLR 2023
BIB ABSTRACT
Recent Self-Supervised Learning (SSL) methods are able to learn feature representations that are invariant to different data augmentations, which can then be transferred to downstream tasks of interest. However, different downstream tasks require different invariances for their best performance, so the optimal choice of augmentations for SSL depends on the target task. In this paper, we aim to learn self-supervised features that generalize well across a variety of downstream tasks (e.g., object classification, detection and instance segmentation) without knowing any task information beforehand. We do so by Masked Augmentation Subspace Training (or MAST) to encode in the single feature space the priors from different data augmentations in a factorized way. Specifically, we disentangle the feature space into separate subspaces, each induced by a learnable mask that selects relevant feature dimensions to model invariance to a specific augmentation. We show the success of MAST in jointly capturing generalizable priors from different augmentations, using both unique and shared features across the subspaces. We further show that MAST benefits from uncertainty modeling to reweight ambiguous samples from strong augmentations that may cause similarity mismatch in each subspace. Experiments demonstrate that MAST consistently improves generalization on various downstream tasks, while being task-agnostic and efficient during SSL. We also provide interesting insights about how different augmentations are related and how uncertainty reflects learning difficulty.
2022
-

-
Progressively-connected Light Field Network for Efficient View Synthesis
Peng Wang, Yuan Liu, Guying Lin, , Lingjie Liu, Taku Komura, Wenping Wang
Arxiv 2022
BIB ABSTRACT
This paper presents a Progressively-connected Light Field network (ProLiF), for the novel view synthesis of complex forward-facing scenes. ProLiF encodes a 4D light field, which allows rendering a large batch of rays in one training step for image- or patch-level losses. Directly learning a neural light field from images has difficulty in rendering multi-view consistent images due to its unawareness of the underlying 3D geometry. To address this problem, we propose a progressive training scheme and regularization losses to infer the underlying geometry during training, both of which enforce the multi-view consistency and thus greatly improves the rendering quality. Experiments demonstrate that our method is able to achieve significantly better rendering quality than the vanilla neural light fields and comparable results to NeRF-like rendering methods on the challenging LLFF dataset and Shiny Object dataset. Moreover, we demonstrate better compatibility with LPIPS loss to achieve robustness to varying light conditions and CLIP loss to control the rendering style of the scene.
-

-
Data2vec: A general framework for self-supervised learning in speech, vision and language
Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, , Michael Auli
ICML 2022
BIB ABSTRACT
While the general idea of self-supervised learning is identical across modalities, the actual algorithms and objectives differ widely because they were developed with a single modality in mind. To get us closer to general self-supervised learning, we present data2vec, a framework that uses the same learning method for either speech, NLP or computer vision. The core idea is to predict latent representations of the full input data based on a masked view of the input in a self-distillation setup using a standard Transformer architecture. Instead of predicting modality-specific targets such as words, visual tokens or units of human speech which are local in nature, data2vec predicts contextualized latent representations that contain information from the entire input. Experiments on the major benchmarks of speech recognition, image classification, and natural language understanding demonstrate a new state of the art or competitive performance to predominant approaches.
-

-
Stylenerf: A style-based 3d-aware generator for high-resolution image synthesis
, Lingjie Liu, Peng Wang, Christian Theobalt
ICLR 2022
BIB ABSTRACT
We propose StyleNeRF, a 3D-aware generative model for photo-realistic high-resolution image synthesis with high multi-view consistency, which can be trained on unstructured 2D images. Existing approaches either cannot synthesize high-resolution images with fine details or yield noticeable 3D-inconsistent artifacts. In addition, many of them lack control over style attributes and explicit 3D camera poses. StyleNeRF integrates the neural radiance field (NeRF) into a style-based generator to tackle the aforementioned challenges, i.e., improving rendering efficiency and 3D consistency for high-resolution image generation. We perform volume rendering only to produce a low-resolution feature map and progressively apply upsampling in 2D to address the first issue. To mitigate the inconsistencies caused by 2D upsampling, we propose multiple designs, including a better upsampler and a new regularization loss. With these designs, StyleNeRF can synthesize high-resolution images at interactive rates while preserving 3D consistency at high quality. StyleNeRF also enables control of camera poses and different levels of styles, which can generalize to unseen views. It also supports challenging tasks, including zoom-in and-out, style mixing, inversion, and semantic editing.
-
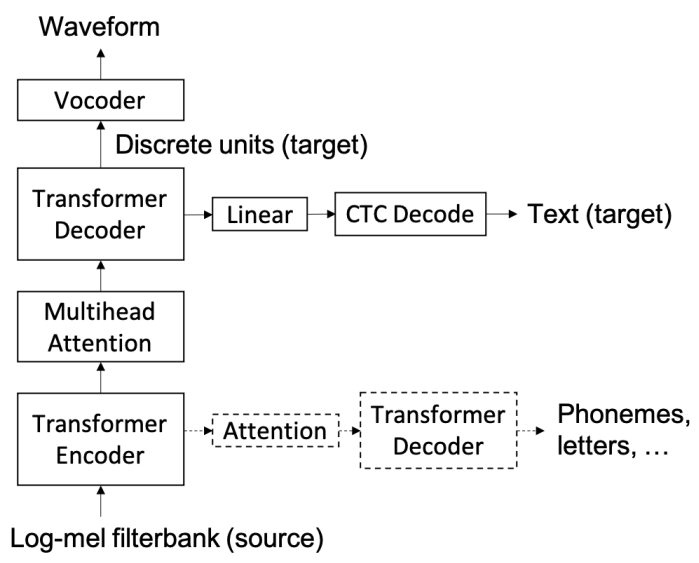
-
Direct Speech-to-Speech Translation With Discrete Units
Ann Lee, Peng-Jen Chen, Changhan Wang, , Sravya Popuri, Xutai Ma, Adam Polyak, Yossi Adi, Qing He, Yun Tang, Juan Pino, Wei-Ning Hsu
ACL 2022
BIB ABSTRACT
We present a direct speech-to-speech translation (S2ST) model that translates speech from one language to speech in another language without relying on intermediate text generation. We tackle the problem by first applying a self-supervised discrete speech encoder on the target speech and then training a sequence-to-sequence speech-to-unit translation (S2UT) model to predict the discrete representations of the target speech. When target text transcripts are available, we design a joint speech and text training framework that enables the model to generate dual modality output (speech and text) simultaneously in the same inference pass. Experiments on the Fisher Spanish-English dataset show that the proposed framework yields improvement of 6.7 BLEU compared with a baseline direct S2ST model that predicts spectrogram features. When trained without any text transcripts, our model performance is comparable to models that predict spectrograms and are trained with text supervision, showing the potential of our system for translation between unwritten languages.
-
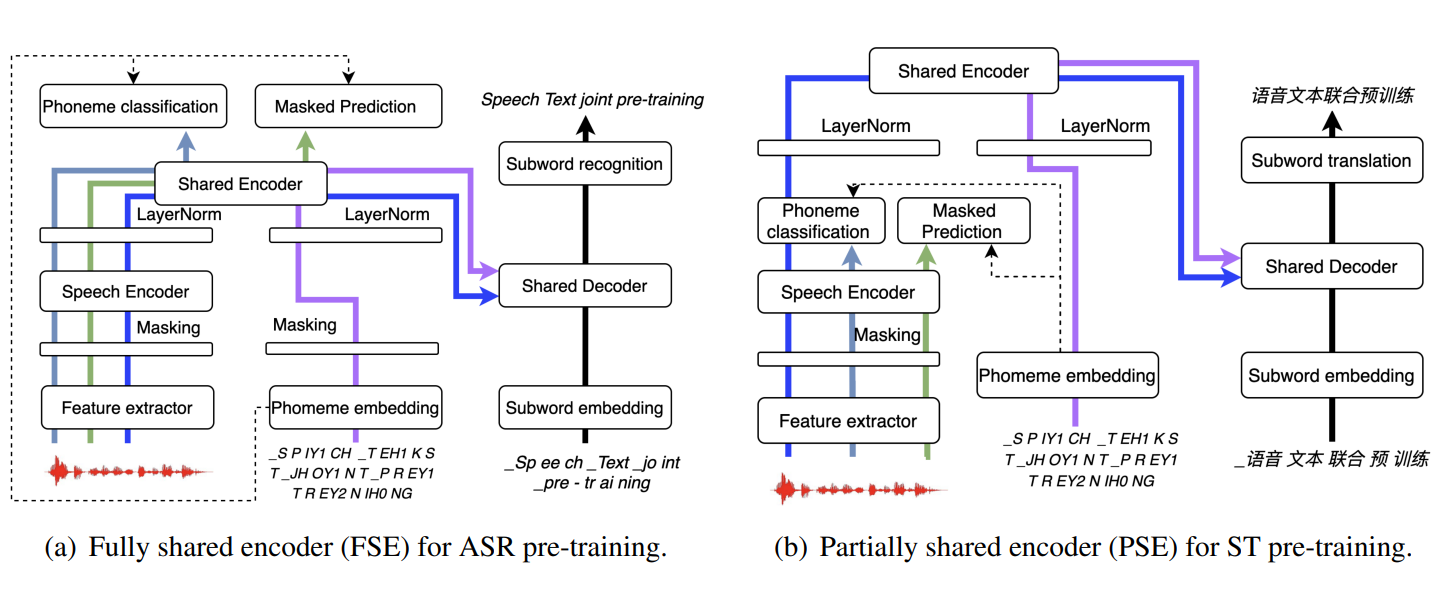
-
Unified Speech-Text Pre-training for Speech Translation and Recognition
Yun Tang, Hongyu Gong, Ning Dong, Changhan Wang, Wei-Ning Hsu, , Alexei Baevski, Xian Li, Abdelrahman Mohamed, Michael Auli, Juan Pino
ACL 2022
BIB ABSTRACT
In this work, we describe a method to jointly pre-train speech and text in an encoder-decoder modeling framework for speech translation and recognition. The proposed method utilizes multi-task learning to integrate four self-supervised and supervised subtasks for cross modality learning. A self-supervised speech subtask, which leverages unlabelled speech data, and a (self-)supervised text to text subtask, which makes use of abundant text training data, take up the majority of the pre-training time. Two auxiliary supervised speech tasks are included to unify speech and text modeling space. Detailed analysis reveals learning interference among subtasks. In order to alleviate the subtask interference, two pre-training configurations are proposed for speech translation and speech recognition respectively. Our experiments show the proposed method can effectively fuse speech and text information into one model. It achieves between 1.7 and 2.3 BLEU improvement above the state of the art on the MuST-C speech translation dataset and comparable WERs to wav2vec 2.0 on the Librispeech speech recognition task.
-

-
Textless Speech-to-Speech Translation on Real Data
Ann Lee, Hongyu Gong, Paul-Ambroise Duquenne, Holger Schwenk, Peng-Jen Chen, Changhan Wang, Sravya Popuri, Juan Pino, , Wei-Ning Hsu
NAACL 2022
BIB ABSTRACT
We present a direct speech-to-speech translation (S2ST) model that translates speech from one language to speech in another language without relying on intermediate text generation. We tackle the problem by first applying a self-supervised discrete speech encoder on the target speech and then training a sequence-to-sequence speech-to-unit translation (S2UT) model to predict the discrete representations of the target speech. When target text transcripts are available, we design a joint speech and text training framework that enables the model to generate dual modality output (speech and text) simultaneously in the same inference pass. Experiments on the Fisher Spanish-English dataset show that the proposed framework yields improvement of 6.7 BLEU compared with a baseline direct S2ST model that predicts spectrogram features. When trained without any text transcripts, our model performance is comparable to models that predict spectrograms and are trained with text supervision, showing the potential of our system for translation between unwritten languages.
-
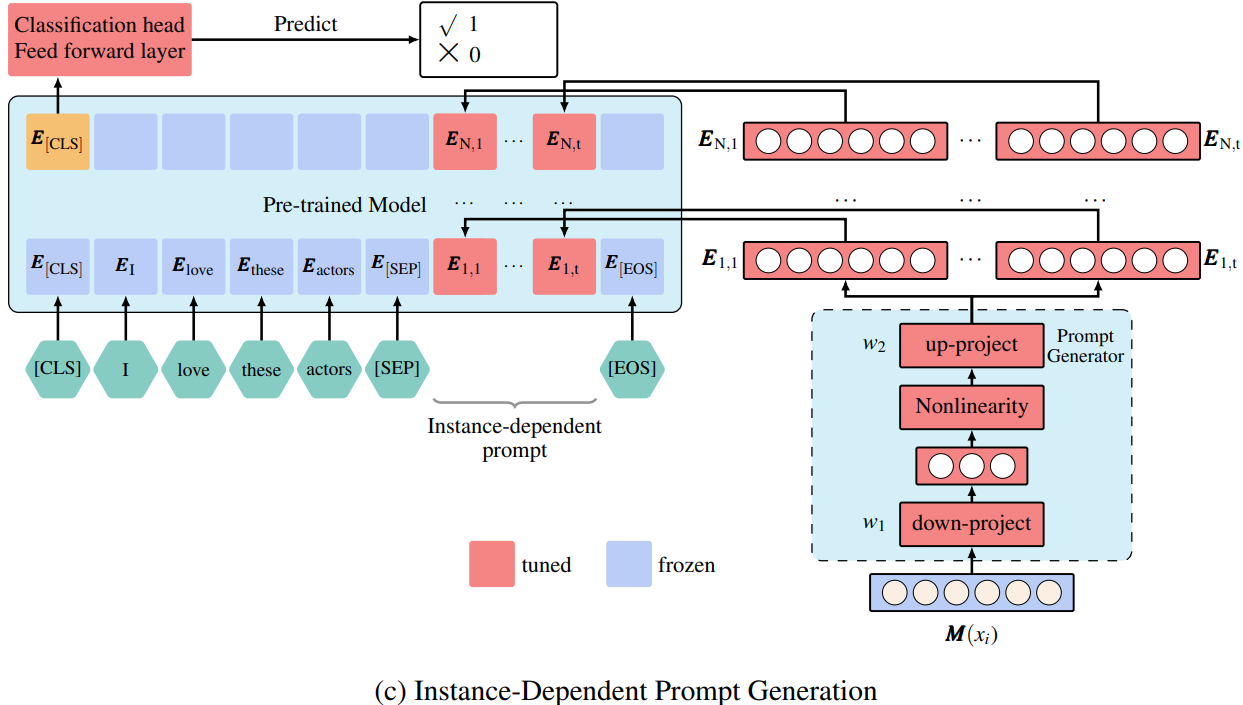
-
IDPG: An instance-dependent prompt generation method
Zhuofeng Wu, Sinong Wang, , Rui Hou, Yuxiao Dong, VG Vydiswaran, Hao Ma
NAACL 2022
BIB ABSTRACT
Prompt tuning is a new, efficient NLP transfer learning paradigm that adds a task-specific prompt in each input instance during the model training stage. It freezes the pre-trained language model and only optimizes a few task-specific prompts. In this paper, we propose a conditional prompt generation method to generate prompts for each input instance, referred to as the Instance-Dependent Prompt Generation (IDPG). Unlike traditional prompt tuning methods that use a fixed prompt, IDPG introduces a lightweight and trainable component to generate prompts based on each input sentence. Extensive experiments on ten natural language understanding (NLU) tasks show that the proposed strategy consistently outperforms various prompt tuning baselines and is on par with other efficient transfer learning methods such as Compacter while tuning far fewer model parameters.
-
-
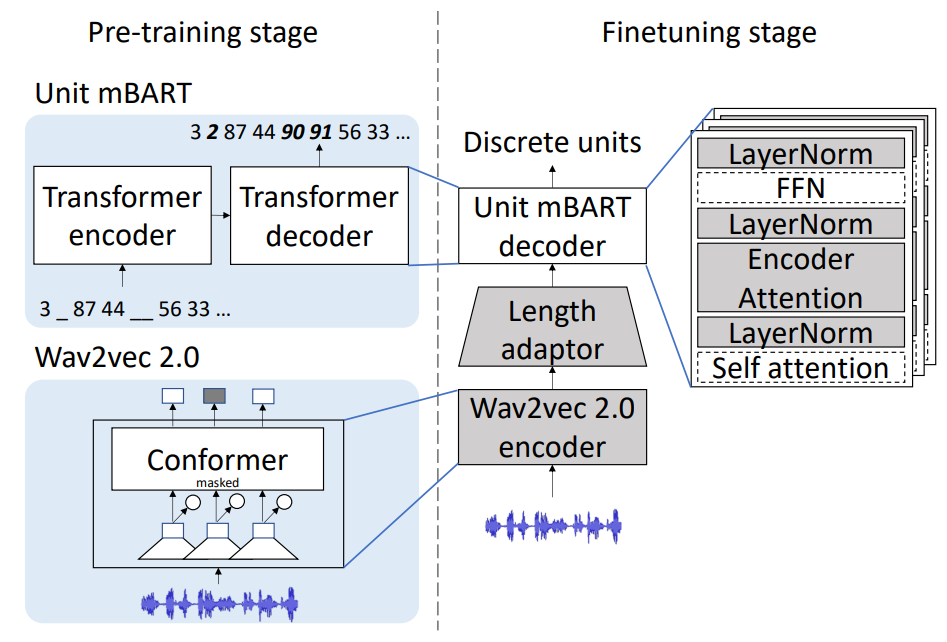
Enhanced Direct Speech-to-Speech Translation Using Self-supervised Pre-training and Data Augmentation
Sravya Popuri, Peng-Jen Chen, Changhan Wang, Juan Pino, Yossi Adi, , Wei-Ning Hsu, Ann Lee
ARXIV Preprint 2022
BIB ABSTRACT
Direct speech-to-speech translation (S2ST) models suffer from data scarcity issues as there exists little parallel S2ST data, compared to the amount of data available for conventional cascaded systems that consist of automatic speech recognition (ASR), machine translation (MT), and text-to-speech (TTS) synthesis. In this work, we explore self-supervised pre-training with unlabeled speech data and data augmentation to tackle this issue. We take advantage of a recently proposed speech-to-unit translation (S2UT) framework that encodes target speech into discrete representations, and transfer pre-training and efficient partial finetuning techniques that work well for speech-to-text translation (S2T) to the S2UT domain by studying both speech encoder and discrete unit decoder pre-training. Our experiments show that self-supervised pre-training consistently improves model performance compared with multitask learning with a BLEU gain of 4.3-12.0 under various data setups, and it can be further combined with data augmentation techniques that apply MT to create weakly supervised training data.
2021
-
-
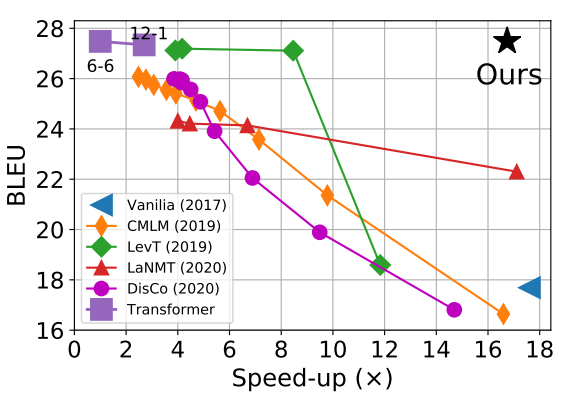
Fully Non-autoregressive Neural Machine Translation: Tricks of the Trade
, Xiang Kong
ACL 2021
BIB ABSTRACT
Fully non-autoregressive neural machine translation (NAT) is proposed to simultaneously predict tokens with single forward of neural networks, which significantly reduces the inference latency at the expense of quality drop compared to the Transformer baseline. In this work, we target on closing the performance gap while maintaining the latency advantage. We first inspect the fundamental issues of fully NAT models, and adopt dependency reduction in the learning space of output tokens as the basic guidance. Then, we revisit methods in four different aspects that have been proven effective for improving NAT models, and carefully combine these techniques with necessary modifications. Our extensive experiments on three translation benchmarks show that the proposed system achieves the new state-of-the-art results for fully NAT models, and obtains comparable performance with the autoregressive and iterative NAT systems. For instance, one of the proposed models achieves 27.49 BLEU points on WMT14 En-De with approximately 16.5X speed up at inference time.
-

-
Detecting hallucinated content in conditional neural sequence generation
Chunting Zhou, Graham Neubig, , Mona Diab, Paco Guzman, Luke Zettlemoyer, Marjan Ghazvininejad
ACL 2021
BIB ABSTRACT
Neural sequence models can generate highly fluent sentences, but recent studies have also shown that they are also prone to hallucinate additional content not supported by the input. These variety of fluent but wrong outputs are particularly problematic, as it will not be possible for users to tell they are being presented incorrect content. To detect these errors, we propose a task to predict whether each token in the output sequence is hallucinated (not contained in the input) and collect new manually annotated evaluation sets for this task. We also introduce a method for learning to detect hallucinations using pretrained language models fine tuned on synthetic data that includes automatically inserted hallucinations Experiments on machine translation (MT) and abstractive summarization demonstrate that our proposed approach consistently outperforms strong baselines on all benchmark datasets. We further demonstrate how to use the token-level hallucination labels to define a fine-grained loss over the target sequence in low-resource MT and achieve significant improvements over strong baseline methods. We also apply our method to word-level quality estimation for MT and show its effectiveness in both supervised and unsupervised settings.
-
-
Multilingual translation from denoising pre-training
Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, , Angela Fan
ACL 2021
BIB ABSTRACT
Recent work demonstrates the potential of training one model for multilingual machine translation. In parallel, denoising pretraining using unlabeled monolingual data as a starting point for finetuning bitext machine translation systems has demonstrated strong performance gains. However, little has been explored on the potential to combine denoising pretraining with multilingual machine translation in a single model. In this work, we fill this gap by studying how multilingual translation models can be created through multilingual finetuning. Fintuning multilingual model from a denoising pretrained model incorporates the benefits of large quantities of unlabeled monolingual data, which is particularly important for low resource languages where bitext is rare. Further, we create the ML50 benchmark to facilitate reproducible research by standardizing training and evaluation data. On ML50, we show that multilingual finetuning significantly improves over multilingual models trained from scratch and bilingual finetuning for translation into English. We also find that multilingual finetuning can significantly improve over multilingual models trained from scratch for zero-shot translation on non-English directions. Finally, we discuss that the pretraining and finetuning paradigm alone is not enough to address the challenges of multilingual models for to-Many directions performance.
-
-
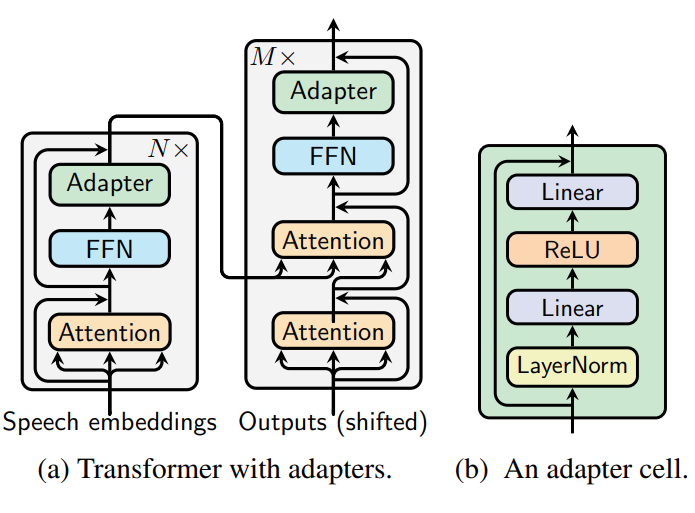
Lightweight Adapter Tuning for Multilingual Speech Translation
Hang Le, Juan Pino, Changhan Wang, , Didier Schwab, Laurent Besacier
ACL 2021
BIB ABSTRACT
Adapter modules were recently introduced as an efficient alternative to fine-tuning in NLP. Adapter tuning consists in freezing pretrained parameters of a model and injecting lightweight modules between layers, resulting in the addition of only a small number of task-specific trainable parameters. While adapter tuning was investigated for multilingual neural machine translation, this paper proposes a comprehensive analysis of adapters for multilingual speech translation (ST). Starting from different pre-trained models (a multilingual ST trained on parallel data or a multilingual BART (mBART) trained on non-parallel multilingual data), we show that adapters can be used to: (a) efficiently specialize ST to specific language pairs with a low extra cost in terms of parameters, and (b) transfer from an automatic speech recognition (ASR) task and an mBART pre-trained model to a multilingual ST task. Experiments show that adapter tuning offer competitive results to full fine-tuning, while being much more parameter-efficient.
-
-
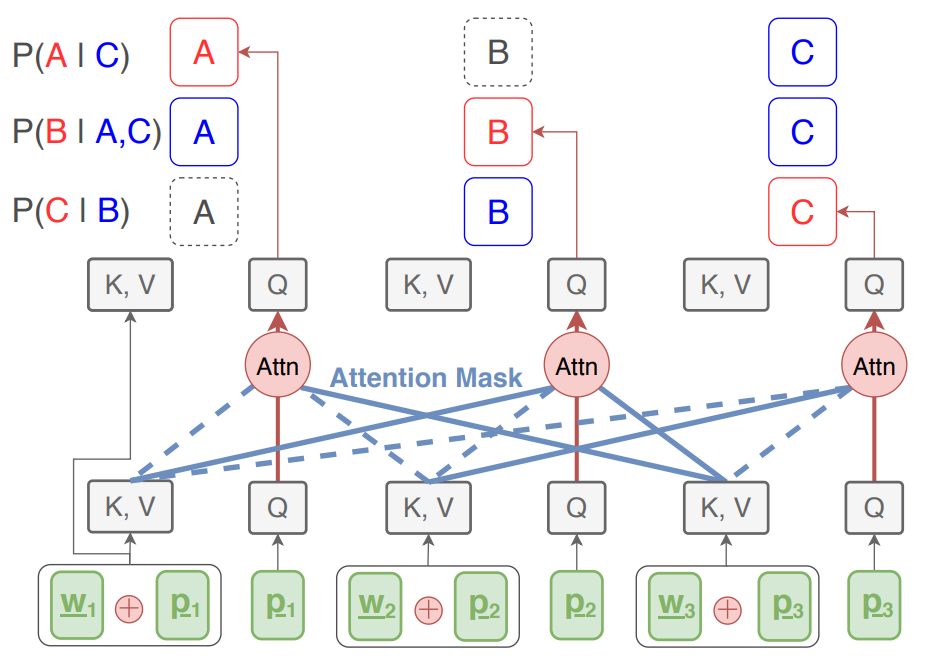
Non-autoregressive machine translation with disentangled context transformer
Jungo Kasai, James Cross, Marjan Ghazvininejad,
ICML 2021
BIB ABSTRACT
State-of-the-art neural machine translation models generate a translation from left to right and every step is conditioned on the previously generated tokens. The sequential nature of this generation process causes fundamental latency in inference since we cannot generate multiple tokens in each sentence in parallel. We propose an attention-masking based model, called Disentangled Context (DisCo) transformer, that simultaneously generates all tokens given different contexts. The DisCo transformer is trained to predict every output token given an arbitrary subset of the other reference tokens. We also develop the parallel easy-first inference algorithm, which iteratively refines every token in parallel and reduces the number of required iterations. Our extensive experiments on 7 translation directions with varying data sizes demonstrate that our model achieves competitive, if not better, performance compared to the state of the art in non-autoregressive machine translation while significantly reducing decoding time on average.
-

-
Volume Rendering of Neural Implicit Surfaces
Lior Yariv, , Yoni Kasten, Yaron Lipman
NeurIPS 2021 (Oral)
BIB ABSTRACT
Neural volume rendering became increasingly popular recently due to its success in synthesizing novel views of a scene from a sparse set of input images. So far, the geometry learned by neural volume rendering techniques was modeled using a generic density function. Furthermore, the geometry itself was extracted using an arbitrary level set of the density function leading to a noisy, often low fidelity reconstruction. The goal of this paper is to improve geometry representation and reconstruction in neural volume rendering. We achieve that by modeling the volume density as a function of the geometry. This is in contrast to previous work modeling the geometry as a function of the volume density. In more detail, we define the volume density function as Laplace's cumulative distribution function (CDF) applied to a signed distance function (SDF) representation. This simple density representation has three benefits:(i) it provides a useful inductive bias to the geometry learned in the neural volume rendering process;(ii) it facilitates a bound on the opacity approximation error, leading to an accurate sampling of the viewing ray. Accurate sampling is important to provide a precise coupling of geometry and radiance; and (iii) it allows efficient unsupervised disentanglement of shape and appearance in volume rendering. Applying this new density representation to challenging scene multiview datasets produced high quality geometry reconstructions, outperforming relevant baselines. Furthermore, switching shape and appearance between scenes is possible due to the disentanglement of the two.
-

-
Neural Actor: Neural Free-view Synthesis of Human Actors with Pose Control
Lingjie Liu, Marc Habermann, Viktor Rudnev, Kripasindhu Sarkar, , Christian Theobalt
SIGGRAPH ASIA 2021
BIB ABSTRACT
We propose Neural Actor (NA), a new method for high-quality synthesis of humans from arbitrary viewpoints and under arbitrary controllable poses. Our method is built upon recent neural scene representation and rendering works which learn representations of geometry and appearance from only 2D images. While existing works demonstrated compelling rendering of static scenes and playback of dynamic scenes, photo-realistic reconstruction and rendering of humans with neural implicit methods, in particular under user-controlled novel poses, is still difficult. To address this problem, we utilize a coarse body model as the proxy to unwarp the surrounding 3D space into a canonical pose. A neural radiance field learns pose-dependent geometric deformations and pose- and view-dependent appearance effects in the canonical space from multi-view video input. To synthesize novel views of high fidelity dynamic geometry and appearance, we leverage 2D texture maps defined on the body model as latent variables for predicting residual deformations and the dynamic appearance. Experiments demonstrate that our method achieves better quality than the state-of-the-arts on playback as well as novel pose synthesis, and can even generalize well to new poses that starkly differ from the training poses. Furthermore, our method also supports body shape control of the synthesized results.
-

-
The source-target domain mismatch problem in machine translation
Jiajun Shen, Peng-Jen Chen, Matthew Le, Junxian He, , Myle Ott, Michael Auli, Marc’Aurelio Ranzato
EACL 2021
BIB ABSTRACT
While we live in an increasingly interconnected world, different places still exhibit strikingly different cultures and many events we experience in our every day life pertain only to the specific place we live in. As a result, people often talk about different things in different parts of the world. In this work we study the effect of local context in machine translation and postulate that this causes the domains of the source and target language to greatly mismatch. We first formalize the concept of source-target domain mismatch, propose a metric to quantify it, and provide empirical evidence for its existence. We conclude with an empirical study of how source-target domain mismatch affects training of machine translation systems on low resource languages. While this may severely affect back-translation, the degradation can be alleviated by combining back-translation with self-training and by increasing the amount of target side monolingual data.
-

-
Multilingual neural machine translation with deep encoder and multiple shallow decoders
Xiang Kong, Adithya Renduchintala, James Cross, Yuqing Tang, , Xian Li
EACL 2021
BIB ABSTRACT
Recent work in multilingual translation advances translation quality surpassing bilingual baselines using deep transformer models with increased capacity. However, the extra latency and memory costs introduced by this approach may make it unacceptable for efficiency-constrained applications. It has recently been shown for bilingual translation that using a deep encoder and shallow decoder (DESD) can reduce inference latency while maintaining translation quality, so we study similar speed-accuracy trade-offs for multilingual translation. We find that for many-to-one translation we can indeed increase decoder speed without sacrificing quality using this approach, but for one-to-many translation, shallow decoders cause a clear quality drop. To ameliorate this drop, we propose a deep encoder with multiple shallow decoders (DEMSD) where each shallow decoder is responsible for a disjoint subset of target languages. Specifically, the DEMSD model with 2-layer decoders is able to obtain a 1.8 x speedup on average compared to a standard transformer model with no drop in translation quality.
-
-
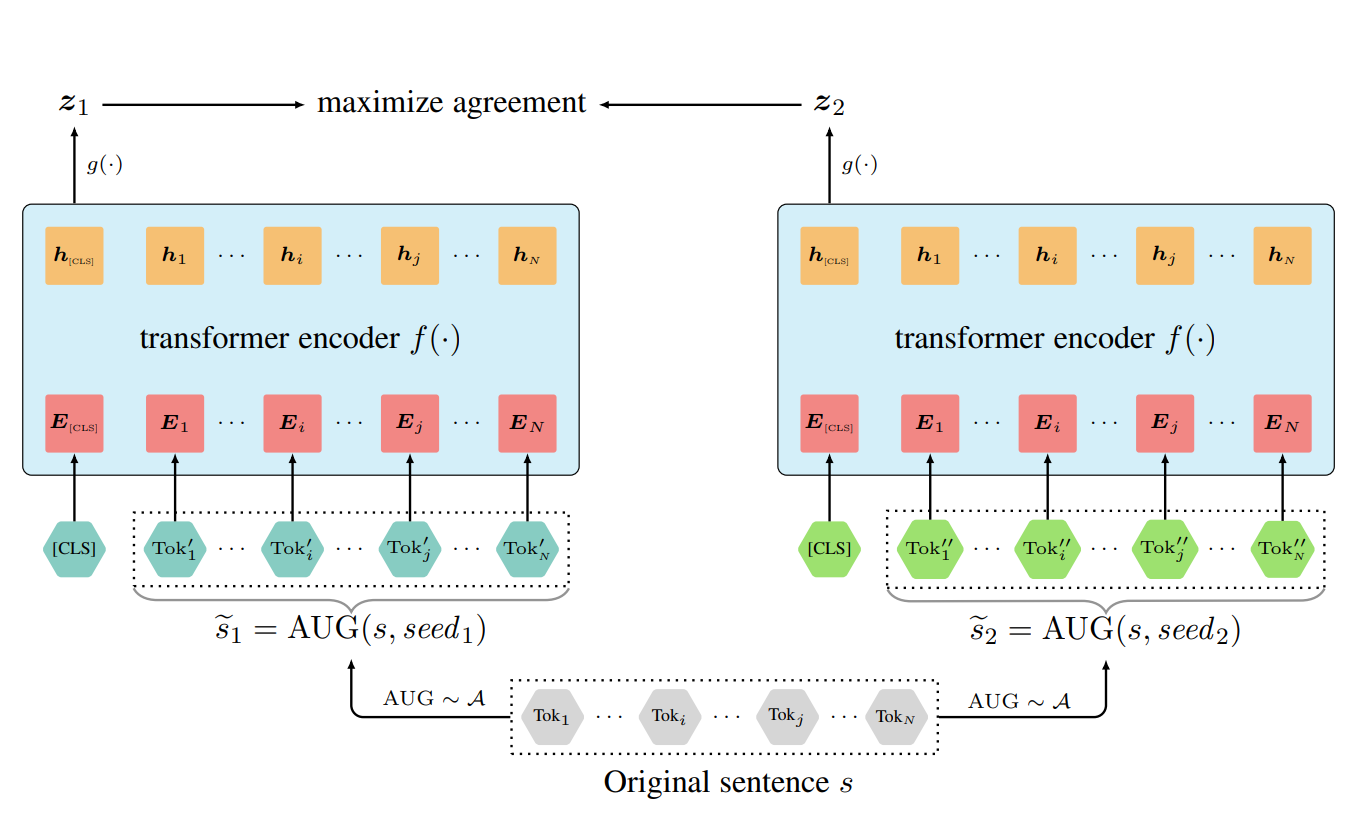
Clear: Contrastive learning for sentence representation
Zhuofeng Wu, Sinong Wang, , Madian Khabsa, Fei Sun, Hao Ma
ARXIV Preprint 2021
BIB ABSTRACT
Pre-trained language models have proven their unique powers in capturing implicit language features. However, most pre-training approaches focus on the word-level training objective, while sentence-level objectives are rarely studied. In this paper, we propose Contrastive LEArning for sentence Representation (CLEAR), which employs multiple sentence-level augmentation strategies in order to learn a noise-invariant sentence representation. These augmentations include word and span deletion, reordering, and substitution. Furthermore, we investigate the key reasons that make contrastive learning effective through numerous experiments. We observe that different sentence augmentations during pre-training lead to different performance improvements on various downstream tasks. Our approach is shown to outperform multiple existing methods on both SentEval and GLUE benchmarks.
-
-
fairseq S^2: A Scalable and Integrable Speech Synthesis Toolkit
Changhan Wang, Wei-Ning Hsu, Yossi Adi, Adam Polyak, Ann Lee, Peng-Jen Chen, , Juan Pino
EMNLP 2021 Demo
BIB ABSTRACT
This paper presents fairseq S^2, a fairseq extension for speech synthesis. We implement a number of autoregressive (AR) and non-AR text-to-speech models, and their multi-speaker variants. To enable training speech synthesis models with less curated data, a number of preprocessing tools are built and their importance is shown empirically. To facilitate faster iteration of development and analysis, a suite of automatic metrics is included. Apart from the features added specifically for this extension, fairseq S^2 also benefits from the scalability offered by fairseq and can be easily integrated with other state-of-the-art systems provided in this framework.
2020
-

-
Multilingual denoising pre-training for neural machine translation
Yinhan Liu*, *, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer
TACL 2020
BIB ABSTRACT
This paper demonstrates that multilingual denoising pre-training produces significant performance gains across a wide variety of machine translation (MT) tasks. We present mBART—a sequence-to-sequence denoising auto-encoder pre-trained on large-scale monolingual corpora in many languages using the BART objective (Lewis et al., 2019). mBART is the first method for pre-training a complete sequence-to-sequence model by denoising full texts in multiple languages, whereas previous approaches have focused only on the encoder, decoder, or reconstructing parts of the text. Pre-training a complete model allows it to be directly fine-tuned for supervised (both sentence-level and document-level) and unsupervised machine translation, with no task- specific modifications. We demonstrate that adding mBART initialization produces performance gains in all but the highest-resource settings, including up to 12 BLEU points for low resource MT and over 5 BLEU points for many document-level and unsupervised models. We also show that it enables transfer to language pairs with no bi-text or that were not in the pre-training corpus, and present extensive analysis of which factors contribute the most to effective pre-training.
-

-
Neural sparse voxel fields
Lingjie Liu*, *, Kyaw Zaw Lin, Tat-Seng Chua, Christian Theobalt
NeurIPS 2020 (Spotlight)
BIB ABSTRACT
Photo-realistic free-viewpoint rendering of real-world scenes using classical computer graphics techniques is challenging, because it requires the difficult step of capturing detailed appearance and geometry models. Recent studies have demonstrated promising results by learning scene representations that implicitly encode both geometry and appearance without 3D supervision. However, existing approaches in practice often show blurry renderings caused by the limited network capacity or the difficulty in finding accurate intersections of camera rays with the scene geometry. Synthesizing high-resolution imagery from these representations often requires time-consuming optical ray marching. In this work, we introduce Neural Sparse Voxel Fields (NSVF), a new neural scene representation for fast and high-quality free-viewpoint rendering. NSVF defines a set of voxel-bounded implicit fields organized in a sparse voxel octree to model local properties in each cell. We progressively learn the underlying voxel structures with a differentiable ray-marching operation from only a set of posed RGB images. With the sparse voxel octree structure, rendering novel views can be accelerated by skipping the voxels containing no relevant scene content. Our method is typically over 10 times faster than the state-of-the-art (namely, NeRF(Mildenhall et al., 2020)) at inference time while achieving higher quality results. Furthermore, by utilizing an explicit sparse voxel representation, our method can easily be applied to scene editing and scene composition. We also demonstrate several challenging tasks, including multi-scene learning, free-viewpoint rendering of a moving human, and large-scale scene rendering.
-
-
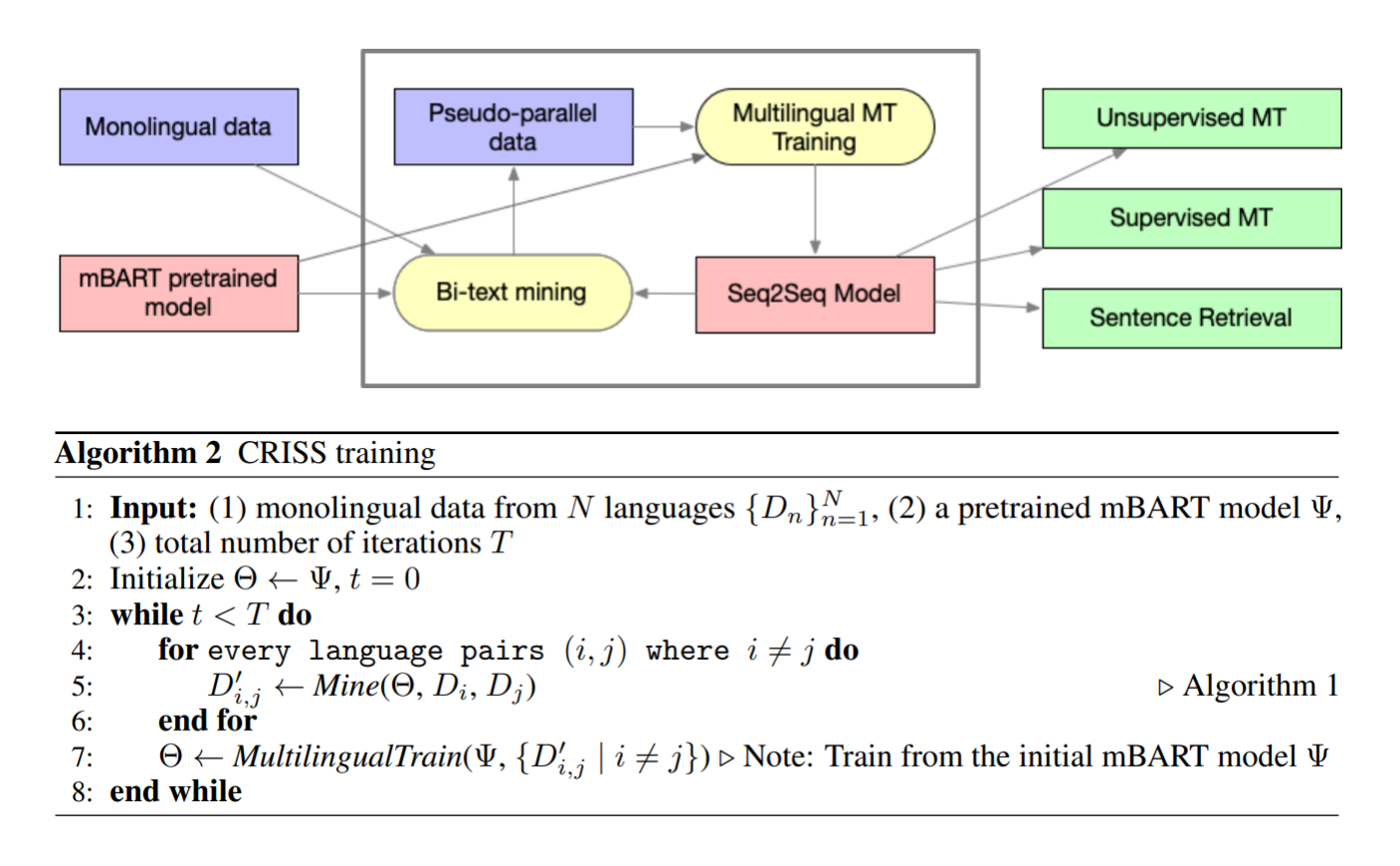
Cross-lingual retrieval for iterative self-supervised training
Chau Tran, Yuqing Tang, Xian Li,
NeurIPS 2020
BIB ABSTRACT
Recent studies have demonstrated the cross-lingual alignment ability of multilingual pretrained language models. In this work, we found that the cross-lingual alignment can be further improved by training seq2seq models on sentence pairs mined using their own encoder outputs. We utilized these findings to develop a new approach---cross-lingual retrieval for iterative self-supervised training (CRISS), where mining and training processes are applied iteratively, improving cross-lingual alignment and translation ability at the same time. Using this method, we achieved state-of-the-art unsupervised machine translation results on 9 language directions with an average improvement of 2.4 BLEU, and on the Tatoeba sentence retrieval task in the XTREME benchmark on 16 languages with an average improvement of 21.5% in absolute accuracy. Furthermore, CRISS also brings an additional 1.8 BLEU improvement on average compared to mBART, when finetuned on supervised machine translation downstream tasks.
-
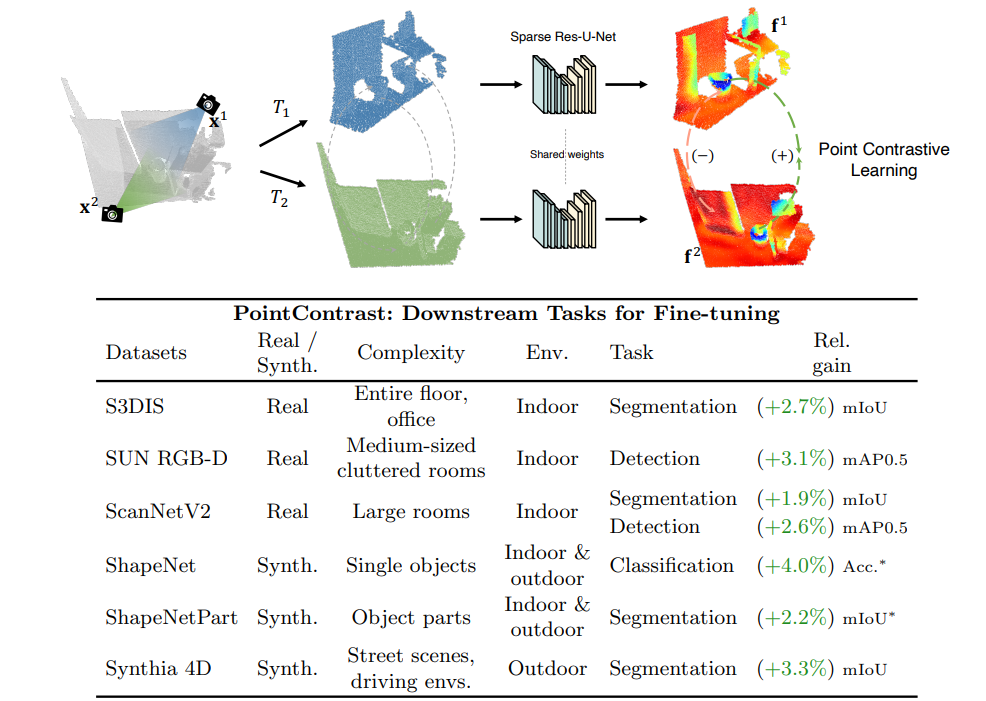
-
PointContrast: Unsupervised pre-training for 3d point cloud understanding
Saining Xie, , Demi Guo, Charles R Qi, Leonidas Guibas, Or Litany
ECCV 2020
BIB ABSTRACT
Arguably one of the top success stories of deep learning is transfer learning. The finding that pre-training a network on a rich source set (e.g., ImageNet) can help boost performance once fine-tuned on a usually much smaller target set, has been instrumental to many applications in language and vision. Yet, very little is known about its usefulness in 3D point cloud understanding. We see this as an opportunity considering the effort required for annotating data in 3D. In this work, we aim at facilitating research on 3D representation learning. Different from previous works, we focus on high-level scene understanding tasks. To this end, we select a suite of diverse datasets and tasks to measure the effect of unsupervised pre-training on a large source set of 3D scenes. Our findings are extremely encouraging: using a unified triplet of architecture, source dataset, and contrastive loss for pre-training, we achieve improvement over recent best results in segmentation and detection across 6 different benchmarks for indoor and outdoor, real and synthetic datasets – demonstrating that the learned representation can generalize across domains. Furthermore, the improvement was similar to supervised pre-training, suggesting that future efforts should favor scaling data collection over more detailed nnotation. We hope these findings will encourage more research on unsupervised pretext task design for 3D deep learning.
-

-
Understanding knowledge distillation in non-autoregressive machine translation
Chunting Zhou*, Graham Neubig, *
ICLR 2020
BIB ABSTRACT
Non-autoregressive machine translation (NAT) systems predict a sequence of output tokens in parallel, achieving substantial improvements in generation speed compared to autoregressive models. Existing NAT models usually rely on the technique of knowledge distillation, which creates the training data from a pretrained autoregressive model for better performance. Knowledge distillation is empirically useful, leading to large gains in accuracy for NAT models, but the reason for this success has, as of yet, been unclear. In this paper, we first design systematic experiments to investigate why knowledge distillation is crucial to NAT training. We find that knowledge distillation can reduce the complexity of data sets and help NAT to model the variations in the output data. Furthermore, a strong correlation is observed between the capacity of an NAT model and the optimal complexity of the distilled data for the best translation quality. Based on these findings, we further propose several approaches that can alter the complexity of data sets to improve the performance of NAT models. We achieve the state-of-the-art performance for the NAT-based models, and close the gap with the autoregressive baseline on WMT14 En-De benchmark.
-
-
Monotonic multihead attention
Xutai Ma, Juan Pino, James Cross, Liezl Puzon,
ICLR 2020
BIB ABSTRACT
Simultaneous machine translation models start generating a target sequence before they have encoded or read the source sequence. Recent approaches for this task either apply a fixed policy on a state-of-the art Transformer model, or a learnable monotonic attention on a weaker recurrent neural network-based structure. In this paper, we propose a new attention mechanism, Monotonic Multihead Attention (MMA), which extends the monotonic attention mechanism to multihead attention. We also introduce two novel and interpretable approaches for latency control that are specifically designed for multiple attentions heads. We apply MMA to the simultaneous machine translation task and demonstrate better latency-quality tradeoffs compared to MILk, the previous state-of-the-art approach. We also analyze how the latency controls affect the attention span and we motivate the introduction of our model by analyzing the effect of the number of decoder layers and heads on quality and latency.
-
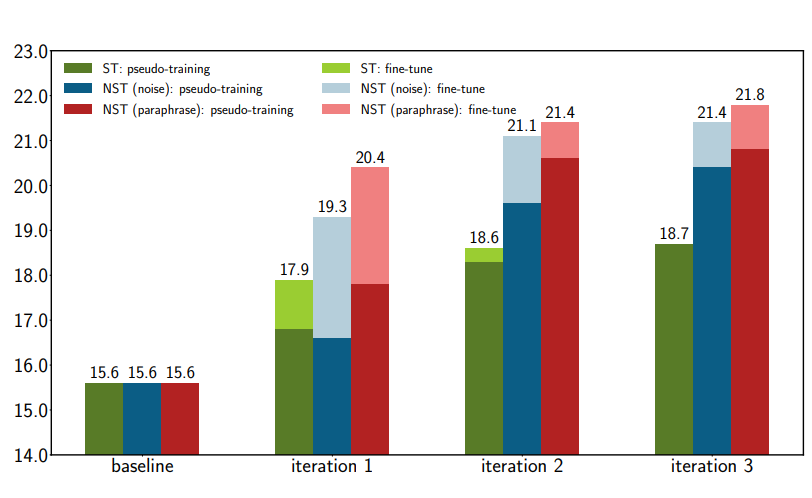
-
Revisiting self-training for neural sequence generation
Junxian He*, *, Jiajun Shen, Marc'Aurelio Ranzato
ICLR 2020
BIB ABSTRACT
Self-training is one of the earliest and simplest semi-supervised methods. The key idea is to augment the original labeled dataset with unlabeled data paired with the model's prediction (i.e. the pseudo-parallel data). While self-training has been extensively studied on classification problems, in complex sequence generation tasks (e.g. machine translation) it is still unclear how self-training works due to the compositionality of the target space. In this work, we first empirically show that self-training is able to decently improve the supervised baseline on neural sequence generation tasks. Through careful examination of the performance gains, we find that the perturbation on the hidden states (i.e. dropout) is critical for self-training to benefit from the pseudo-parallel data, which acts as a regularizer and forces the model to yield close predictions for similar unlabeled inputs. Such effect helps the model correct some incorrect predictions on unlabeled data. To further encourage this mechanism, we propose to inject noise to the input space, resulting in a "noisy" version of self-training. Empirical study on standard machine translation and text summarization benchmarks shows that noisy self-training is able to effectively utilize unlabeled data and improve the performance of the supervised baseline by a large margin.
-
-
Depth-adaptive transformer
Maha Elbayad, , Edouard Grave, Michael Auli
ICLR 2020
BIB ABSTRACT
State of the art sequence-to-sequence models for large scale tasks perform a fixed number of computations for each input sequence regardless of whether it is easy or hard to process. In this paper, we train Transformer models which can make output predictions at different stages of the network and we investigate different ways to predict how much computation is required for a particular sequence. Unlike dynamic computation in Universal Transformers, which applies the same set of layers iteratively, we apply different layers at every step to adjust both the amount of computation as well as the model capacity. On IWSLT German-English translation our approach matches the accuracy of a well tuned baseline Transformer while using less than a quarter of the decoder layers.
-
-
CoVoST: A diverse multilingual speech-to-text translation corpus
Changhan Wang, Juan Pino, Anne Wu,
LERC 2020
BIB ABSTRACT
Spoken language translation has recently witnessed a resurgence in popularity, thanks to the development of end-to-end models and the creation of new corpora, such as Augmented LibriSpeech and MuST-C. Existing datasets involve language pairs with English as a source language, involve very specific domains or are low resource. We introduce CoVoST, a multilingual speech-to-text translation corpus from 11 languages into English, diversified with over 11,000 speakers and over 60 accents. We describe the dataset creation methodology and provide empirical evidence of the quality of the data. We also provide initial benchmarks, including, to our knowledge, the first end-to-end many-to-one multilingual models for spoken language translation. CoVoST is released under CC0 license and free to use. We also provide additional evaluation data derived from Tatoeba under CC licenses.
-

-
Neural machine translation with byte-level subwords
Changhan Wang, Kyunghyun Cho,
AAAI 2020
BIB ABSTRACT
Almost all existing machine translation models are built on top of character-based vocabularies: characters, subwords or words. Rare characters from noisy text or character-rich languages such as Japanese and Chinese however can unnecessarily take up vocabulary slots and limit its compactness. Representing text at the level of bytes and using the 256 byte set as vocabulary is a potential solution to this issue. High computational cost has however prevented it from being widely deployed or used in practice. In this paper, we investigate byte-level subwords, specifically byte-level BPE (BBPE), which is compacter than character vocabulary and has no out-of-vocabulary tokens, but is more efficient than using pure bytes only is. We claim that contextualizing BBPE embeddings is necessary, which can be implemented by a convolutional or recurrent layer. Our experiments show that BBPE has comparable performance to BPE while its size is only 1/8 of that for BPE. In the multilingual setting, BBPE maximizes vocabulary sharing across many languages and achieves better translation quality. Moreover, we show that BBPE enables transferring models between languages with non-overlapping character sets.
-
-
Improving Cross-Lingual Transfer Learning for End-to-End Speech Recognition with Speech Translation
Changhan Wang, Juan Pino,
Interspeech 2020
BIB ABSTRACT
Transfer learning from high-resource languages is known to be an efficient way to improve end-to-end automatic speech recognition (ASR) for low-resource languages. Pre-trained or jointly trained encoder-decoder models, however, do not share the language modeling (decoder) for the same language, which is likely to be inefficient for distant target languages. We introduce speech-to-text translation (ST) as an auxiliary task to incorporate additional knowledge of the target language and enable transferring from that target language. Specifically, we first translate high-resource ASR transcripts into a target low-resource language, with which a ST model is trained. Both ST and target ASR share the same attention-based encoder-decoder architecture and vocabulary. The former task then provides a fully pre-trained model for the latter, bringing up to 24.6% word error rate (WER) reduction to the baseline (direct transfer from high-resource ASR). We show that training ST with human translations is not necessary. ST trained with machine translation (MT) pseudo-labels brings consistent gains. It can even outperform those using human labels when transferred to target ASR by leveraging only 500K MT examples. Even with pseudo-labels from low-resource MT (200K examples), ST-enhanced transfer brings up to 8.9% WER reduction to direct transfer.
-

-
Self-supervised representations improve end-to-end speech translation
Anne Wu, Changhan Wang, Juan Pino,
Interspeech 2020
BIB ABSTRACT
End-to-end speech-to-text translation can provide a simpler and smaller system but is facing the challenge of data scarcity. Pre-training methods can leverage unlabeled data and have been shown to be effective on data-scarce settings. In this work, we explore whether self-supervised pre-trained speech representations can benefit the speech translation task in both high- and low-resource settings, whether they can transfer well to other languages, and whether they can be effectively combined with other common methods that help improve low-resource end-to-end speech translation such as using a pre-trained high-resource speech recognition system. We demonstrate that self-supervised pre-trained features can consistently improve the translation performance, and cross-lingual transfer allows to extend to a variety of languages without or with little tuning.
-
-
Addressing Posterior Collapse with Mutual Information for Improved Variational Neural Machine Translation
Arya D McCarthy, Xian Li, , Ning Dong
ACL 2020
BIB ABSTRACT
This paper proposes a simple and effective approach to address the problem of posterior collapse in conditional variational autoencoders (CVAEs). It thus improves performance of machine translation models that use noisy or monolingual data, as well as in conventional settings. Extending Transformer and conditional VAEs, our proposed latent variable model measurably prevents posterior collapse by (1) using a modified evidence lower bound (ELBO) objective which promotes mutual information between the latent variable and the target, and (2) guiding the latent variable with an auxiliary bag-of-words prediction task. As a result, the proposed model yields improved translation quality compared to existing variational NMT models on WMT Ro↔ En and De↔ En. With latent variables being effectively utilized, our model demonstrates improved robustness over non-latent Transformer in handling uncertainty: exploiting noisy source-side monolingual data (up to+ 3.2 BLEU), and training with weakly aligned web-mined parallel data (up to+ 4.7 BLEU).
-
-
Simuleval: An evaluation toolkit for simultaneous translation
Xutai Ma, Mohammad Javad Dousti, Changhan Wang, , Juan Pino
EMNLP 2020 Demo
BIB ABSTRACT
Simultaneous translation on both text and speech focuses on a real-time and low-latency scenario where the model starts translating before reading the complete source input. Evaluating simultaneous translation models is more complex than offline models because the latency is another factor to consider in addition to translation quality. The research community, despite its growing focus on novel modeling approaches to simultaneous translation, currently lacks a universal evaluation procedure. Therefore, we present SimulEval, an easy-to-use and general evaluation toolkit for both simultaneous text and speech translation. A server-client scheme is introduced to create a simultaneous translation scenario, where the server sends source input and receives predictions for evaluation and the client executes customized policies. Given a policy, it automatically performs simultaneous decoding and collectively reports several popular latency metrics. We also adapt latency metrics from text simultaneous translation to the speech task. Additionally, SimulEval is equipped with a visualization interface to provide better understanding of the simultaneous decoding process of a system. SimulEval has already been extensively used for the IWSLT 2020 shared task on simultaneous speech translation. Code will be released upon publication.
-
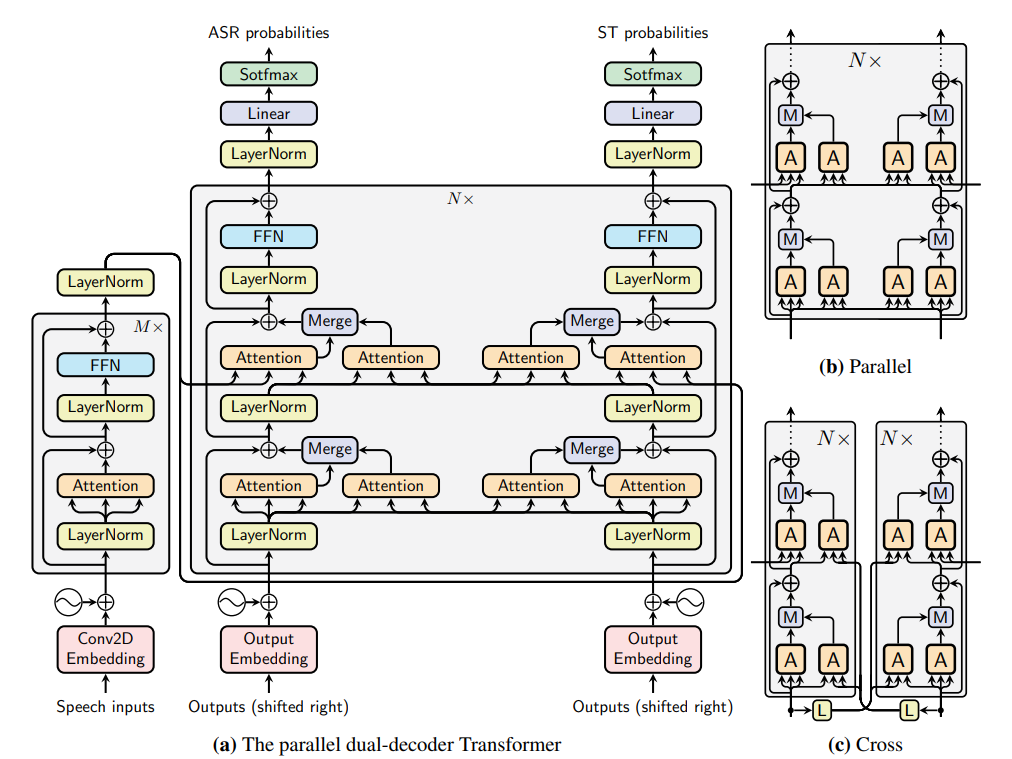
-
Dual-decoder transformer for joint automatic speech recognition and multilingual speech translation
Hang Le, Juan Pino, Changhan Wang, , Didier Schwab, Laurent Besacier
COLING 2020
BIB ABSTRACT
We introduce dual-decoder Transformer, a new model architecture that jointly performs automatic speech recognition (ASR) and multilingual speech translation (ST). Our models are based on the original Transformer architecture (Vaswani et al., 2017) but consist of two decoders, each responsible for one task (ASR or ST). Our major contribution lies in how these decoders interact with each other: one decoder can attend to different information sources from the other via a dual-attention mechanism. We propose two variants of these architectures corresponding to two different levels of dependencies between the decoders, called the parallel and cross dual-decoder Transformers, respectively. Extensive experiments on the MuST-C dataset show that our models outperform the previously-reported highest translation performance in the multilingual settings, and outperform as well bilingual one-to-one results. Furthermore, our parallel models demonstrate no trade-off between ASR and ST compared to the vanilla multi-task architecture.
2019
-
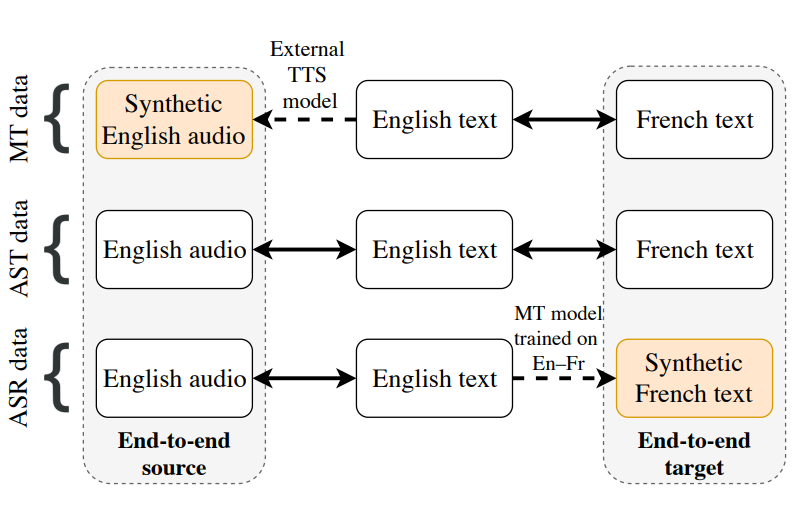
-
Harnessing indirect training data for end-to-end automatic speech translation: Tricks of the trade
Juan Pino, Liezl Puzon, , Xutai Ma, Arya D McCarthy, Deepak Gopinath
IWSLT 2019
BIB ABSTRACT
For automatic speech translation (AST), end-to-end approaches are outperformed by cascaded models that transcribe with automatic speech recognition (ASR), then translate with machine translation (MT). A major cause of the performance gap is that, while existing AST corpora are small, massive datasets exist for both the ASR and MT subsystems. In this work, we evaluate several data augmentation and pretraining approaches for AST, by comparing all on the same datasets. Simple data augmentation by translating ASR transcripts proves most effective on the English--French augmented LibriSpeech dataset, closing the performance gap from 8.2 to 1.4 BLEU, compared to a very strong cascade that could directly utilize copious ASR and MT data. The same end-to-end approach plus fine-tuning closes the gap on the English--Romanian MuST-C dataset from 6.7 to 3.7 BLEU. In addition to these results, we present practical recommendations for augmentation and pretraining approaches. Finally, we decrease the performance gap to 0.01 BLEU using a Transformer-based architecture.
-
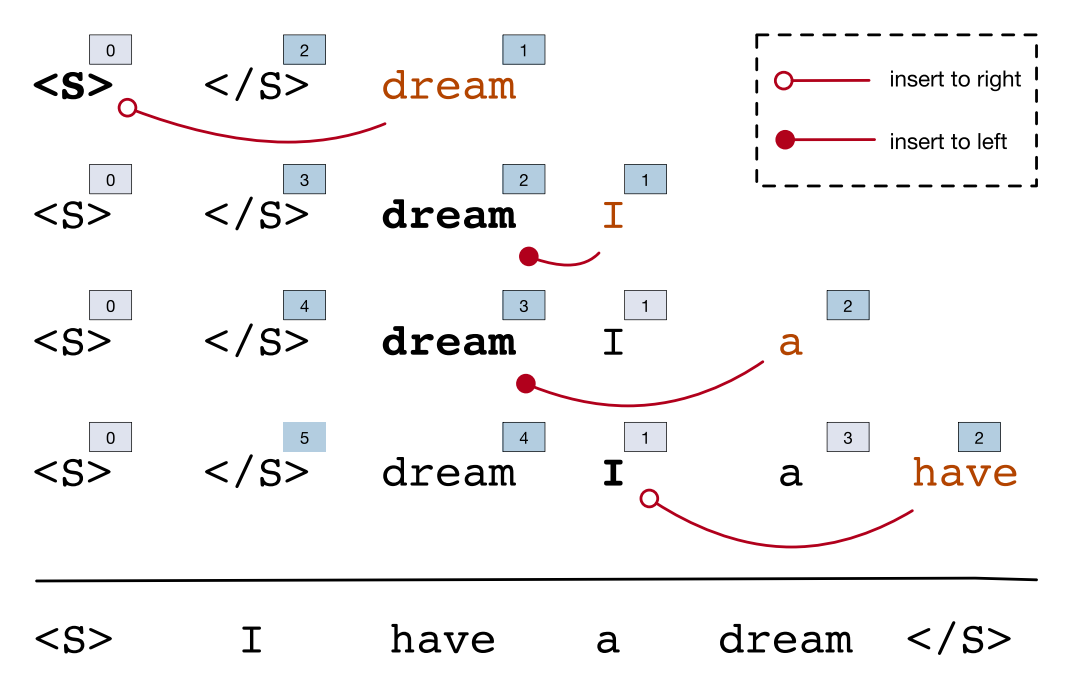
-
Insertion-based decoding with automatically inferred generation order
, Qi Liu, Kyunghyun Cho
TACL 2019
BIB ABSTRACT
Conventional neural autoregressive decoding commonly assumes a fixed left-to-right generation order, which may be sub-optimal. In this work, we propose a novel decoding algorithm— InDIGO—which supports flexible sequence generation in arbitrary orders through insertion operations. We extend Transformer, a state-of-the-art sequence generation model, to efficiently implement the proposed approach, enabling it to be trained with either a pre-defined generation order or adaptive orders obtained from beam-search. Experiments on four real-world tasks, including word order recovery, machine translation, image caption, and code generation, demonstrate that our algorithm can generate sequences following arbitrary orders, while achieving competitive or even better performance compared with the conventional left-to-right generation. The generated sequences show that InDIGO adopts adaptive generation orders based on input information.
-
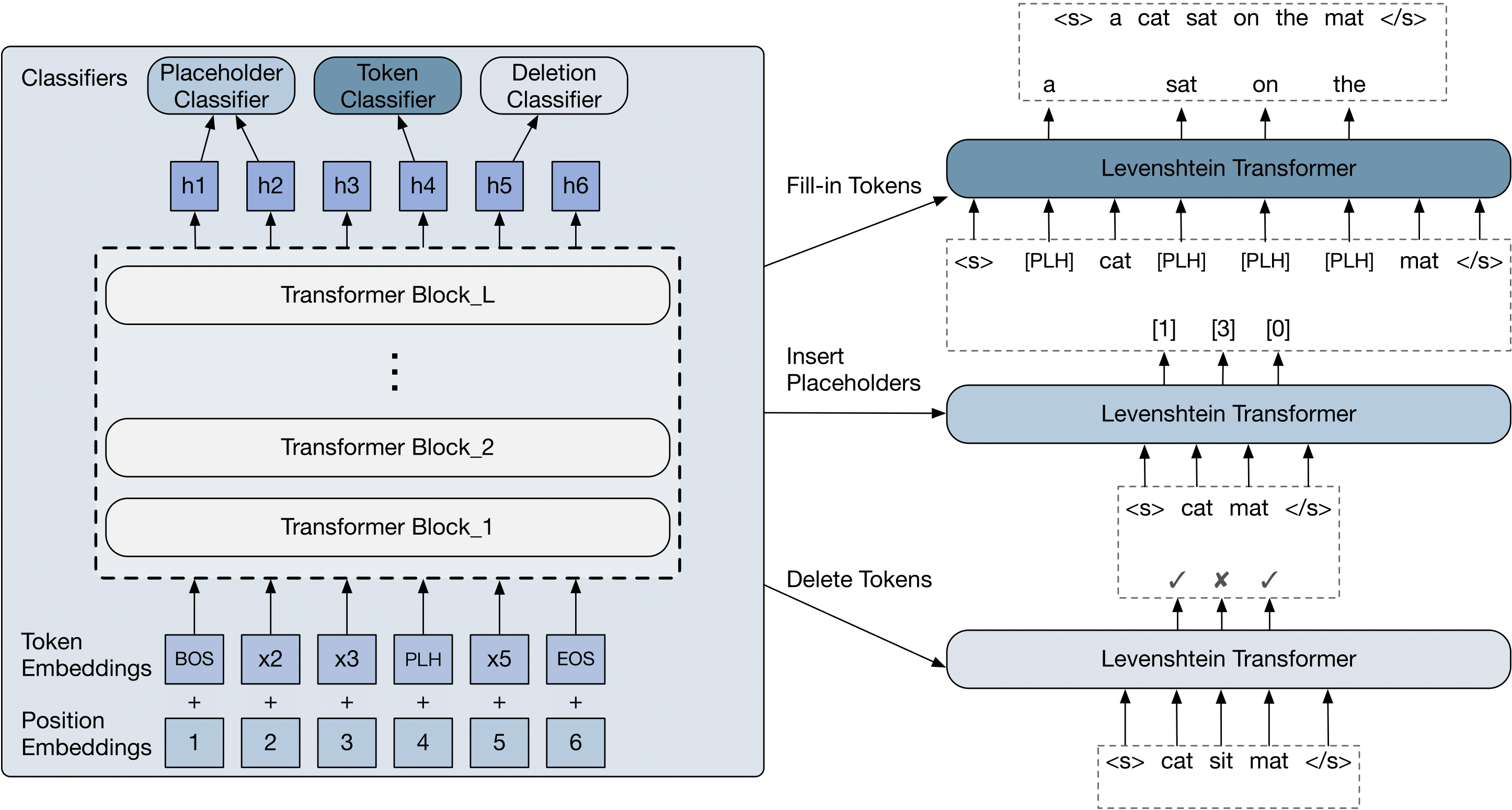
-
Levenshtein Transformer
, Changhan Wang, Jake Zhao
NeurIPS 2019
BIB ABSTRACT
Modern neural sequence generation models are built to either generate tokens step-by-step from scratch or (iteratively) modify a sequence of tokens bounded by a fixed length. In this work, we develop Levenshtein Transformer, a new partially autoregressive model devised for more flexible and amenable sequence generation. Unlike previous approaches, the basic operations of our model are insertion and deletion. The combination of them facilitates not only generation but also sequence refinement allowing dynamic length changes. We also propose a set of new training techniques dedicated at them, effectively exploiting one as the other's learning signal thanks to their complementary nature. Experiments applying the proposed model achieve comparable or even better performance with much-improved efficiency on both generation (eg machine translation, text summarization) and refinement tasks (eg automatic post-editing). We further confirm the flexibility of our model by showing a Levenshtein Transformer trained by machine translation can straightforwardly be used for automatic post-editing.
-
-
Improved Zero-shot Neural Machine Translation via Ignoring Spurious Correlations
, Yong Wang, Kyunghyun Cho, Victor OK Li
ACL 2019
BIB ABSTRACT
Zero-shot translation, translating between language pairs on which a Neural Machine Translation (NMT) system has never been trained, is an emergent property when training the system in multilingual settings. However, naive training for zero-shot NMT easily fails, and is sensitive to hyper-parameter setting. The performance typically lags far behind the more conventional pivot-based approach which translates twice using a third language as a pivot. In this work, we address the degeneracy problem due to capturing spurious correlations by quantitatively analyzing the mutual information between language IDs of the source and decoded sentences. Inspired by this analysis, we propose to use two simple but effective approaches: (1) decoder pre-training; (2) back-translation. These methods show significant improvement (4~22 BLEU points) over the vanilla zero-shot translation on three challenging multilingual datasets, and achieve similar or better results than the pivot-based approach.
-
-
VizSeq: A Visual Analysis Toolkit for Text Generation Tasks
Changhan Wang, Anirudh Jain, Danlu Chen,
EMNLP 2019 Demo
BIB ABSTRACT
Automatic evaluation of text generation tasks (e.g. machine translation, text summarization, image captioning and video description) usually relies heavily on task-specific metrics, such as BLEU and ROUGE. They, however, are abstract numbers and are not perfectly aligned with human assessment. This suggests inspecting detailed examples as a complement to identify system error patterns. In this paper, we present VizSeq, a visual analysis toolkit for instance-level and corpus-level system evaluation on a wide variety of text generation tasks. It supports multimodal sources and multiple text references, providing visualization in Jupyter notebook or a web app interface. It can be used locally or deployed onto public servers for centralized data hosting and benchmarking. It covers most common n-gram based metrics accelerated with multiprocessing, and also provides latest embedding-based metrics such as BERTScore.
2018
-
-
Non-Autoregressive Neural Machine Translation
, James Bradbury, Caiming Xiong, Victor OK Li, Richard Socher
ICLR 2018
BIB ABSTRACT
Existing approaches to neural machine translation condition each output word on previously generated outputs. We introduce a model that avoids this autoregressive property and produces its outputs in parallel, allowing an order of magnitude lower latency during inference. Through knowledge distillation, the use of input token fertilities as a latent variable, and policy gradient fine-tuning, we achieve this at a cost of as little as 2.0 BLEU points relative to the autoregressive Transformer network used as a teacher. We demonstrate substantial cumulative improvements associated with each of the three aspects of our training strategy, and validate our approach on IWSLT 2016 English-German and two WMT language pairs. By sampling fertilities in parallel at inference time, our non-autoregressive model achieves near-state-of-the-art performance of 29.8 BLEU on WMT 2016 English-Romanian.
-
-
Meta-Learning for Low-Resource Neural Machine Translation
, Yong Wang, Yun Chen, Kyunghyun Cho, Victor OK Li
EMNLP 2018
BIB ABSTRACT
In this paper, we propose to extend the recently introduced model-agnostic meta-learning algorithm (MAML) for low-resource neural machine translation (NMT). We frame low-resource translation as a meta-learning problem, and we learn to adapt to low-resource languages based on multilingual high-resource language tasks. We use the universal lexical representation~\citep{gu2018universal} to overcome the input-output mismatch across different languages. We evaluate the proposed meta-learning strategy using eighteen European languages (Bg, Cs, Da, De, El, Es, Et, Fr, Hu, It, Lt, Nl, Pl, Pt, Sk, Sl, Sv and Ru) as source tasks and five diverse languages (Ro, Lv, Fi, Tr and Ko) as target tasks. We show that the proposed approach significantly outperforms the multilingual, transfer learning based approach~\citep{zoph2016transfer} and enables us to train a competitive NMT system with only a fraction of training examples. For instance, the proposed approach can achieve as high as 22.04 BLEU on Romanian-English WMT'16 by seeing only 16,000 translated words (~600 parallel sentences).
-
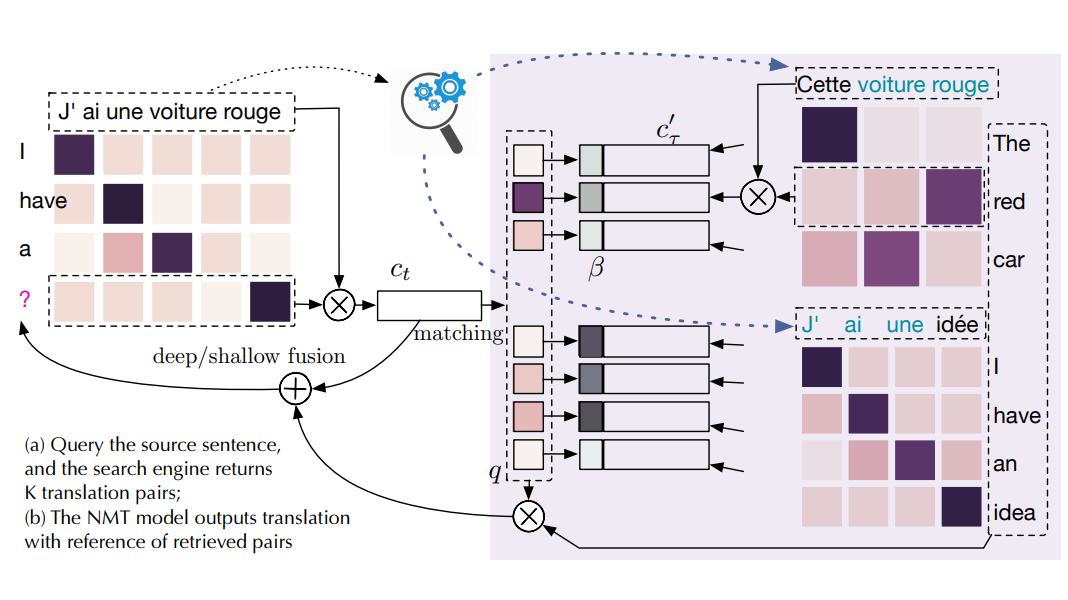
-
Search Engine Guided Neural Machine Translation
, Yong Wang, Kyunghyun Cho, Victor OK Li
AAAI 2018
BIB ABSTRACT
In this paper, we extend an attention-based neural machine translation (NMT) model by allowing it to access an entire training set of parallel sentence pairs even after training. The proposed approach consists of two stages. In the first stage--retrieval stage--, an off-the-shelf, black-box search engine is used to retrieve a small subset of sentence pairs from a training set given a source sentence. These pairs are further filtered based on a fuzzy matching score based on edit distance. In the second stage--translation stage--, a novel translation model, called translation memory enhanced NMT (TM-NMT), seamlessly uses both the source sentence and a set of retrieved sentence pairs to perform the translation. Empirical evaluation on three language pairs (En-Fr, En-De, and En-Es) shows that the proposed approach significantly outperforms the baseline approach and the improvement is more significant when more relevant sentence pairs were retrieved.
-
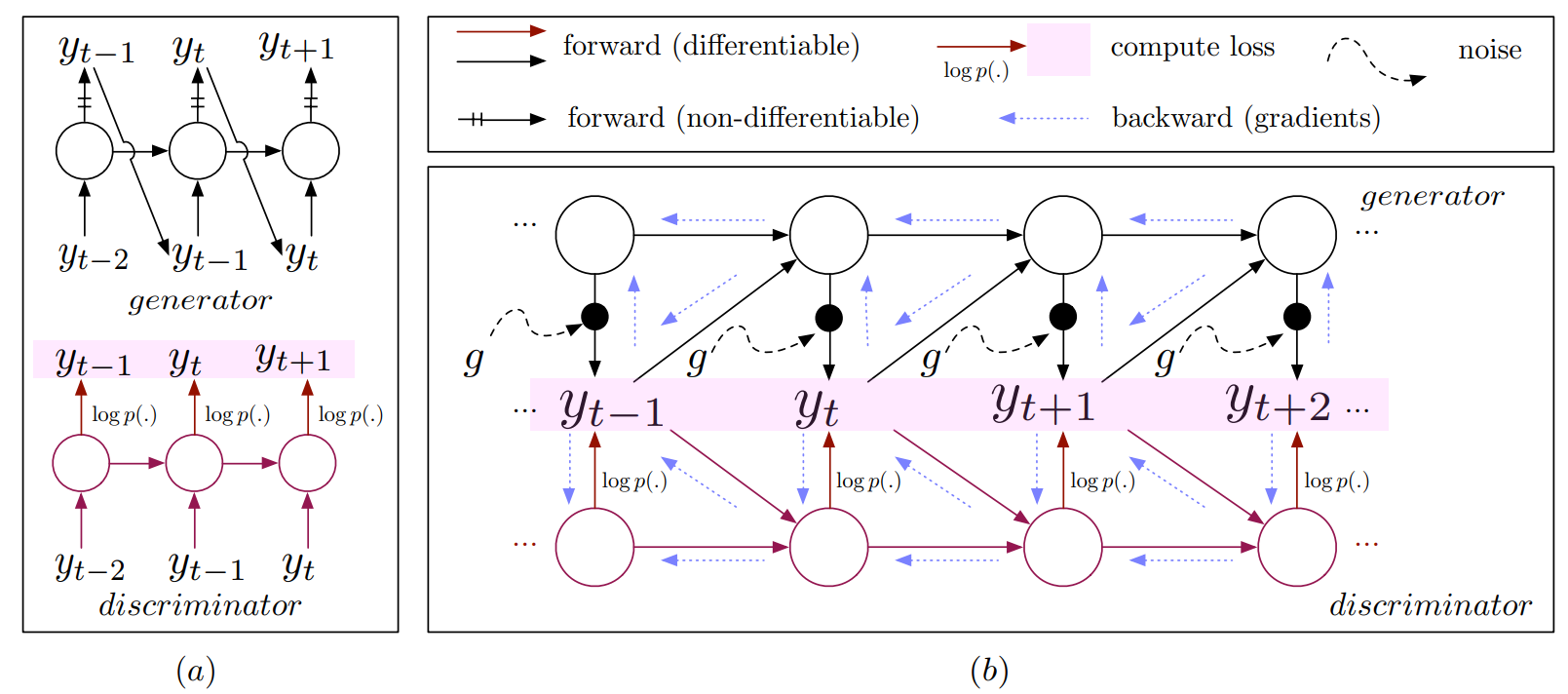
-
Neural machine translation with gumbel-greedy decoding
, Daniel Jiwoong Im, Victor OK Li
AAAI 2018
BIB ABSTRACT
Previous neural machine translation models used some heuristic search algorithms (eg, beam search) in order to avoid solving the maximum a posteriori problem over translation sentences at test phase. In this paper, we propose the\textit {Gumbel-Greedy Decoding} which trains a generative network to predict translation under a trained model. We solve such a problem using the Gumbel-Softmax reparameterization, which makes our generative network differentiable and trainable through standard stochastic gradient methods. We empirically demonstrate that our proposed model is effective for generating sequences of discrete words.
-
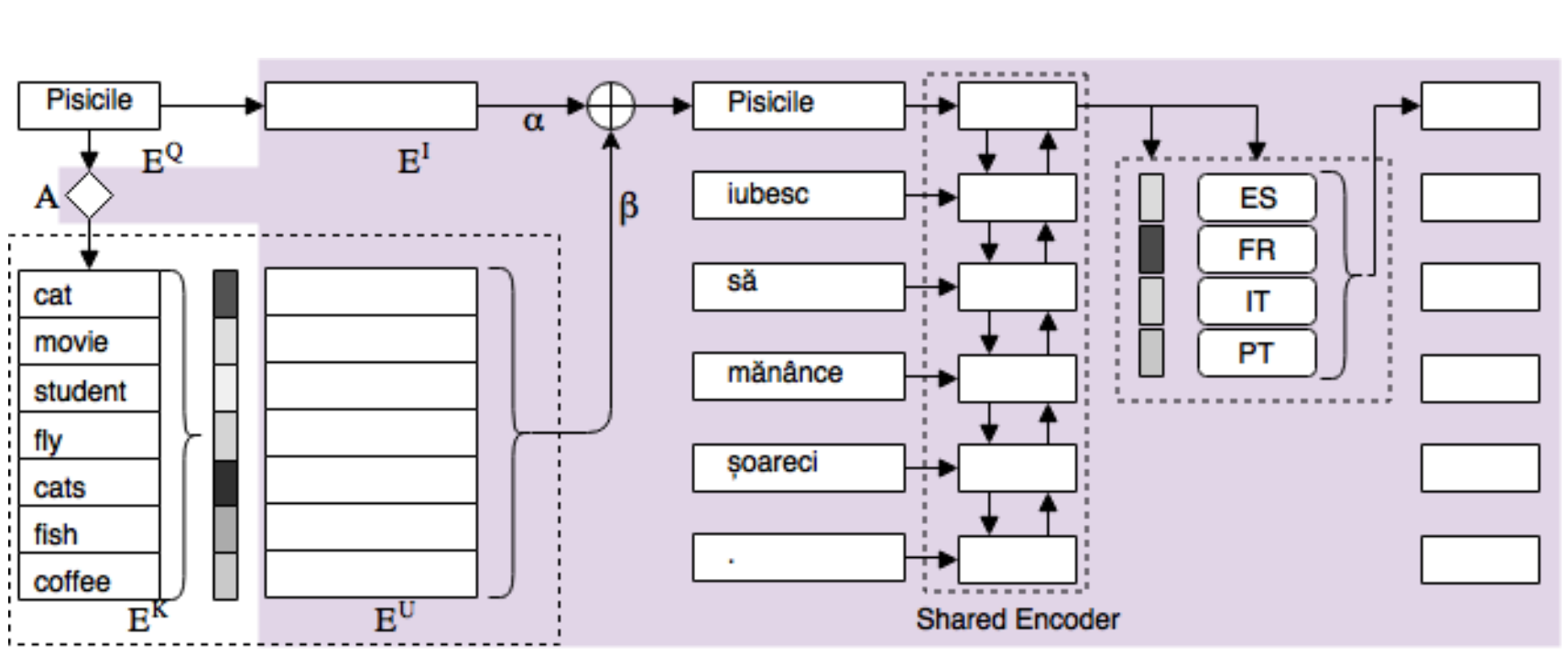
-
Universal Neural Machine Translation for Extremely Low Resource Languages
, Hany Hassan, Jacob Devlin, Victor OK Li
NAACL 2018
BIB ABSTRACT
In this paper, we propose a new universal machine translation approach focusing on languages with a limited amount of parallel data. Our proposed approach utilizes a transfer-learning approach to share lexical and sentence level representations across multiple source languages into one target language. The lexical part is shared through a Universal Lexical Representation to support multilingual word-level sharing. The sentence-level sharing is represented by a model of experts from all source languages that share the source encoders with all other languages. This enables the low-resource language to utilize the lexical and sentence representations of the higher resource languages. Our approach is able to achieve 23 BLEU on Romanian-English WMT2016 using a tiny parallel corpus of 6k sentences, compared to the 18 BLEU of strong baseline system which uses multilingual training and back-translation. Furthermore, we show that the proposed approach can achieve almost 20 BLEU on the same dataset through fine-tuning a pre-trained multi-lingual system in a zero-shot setting.
2017
-
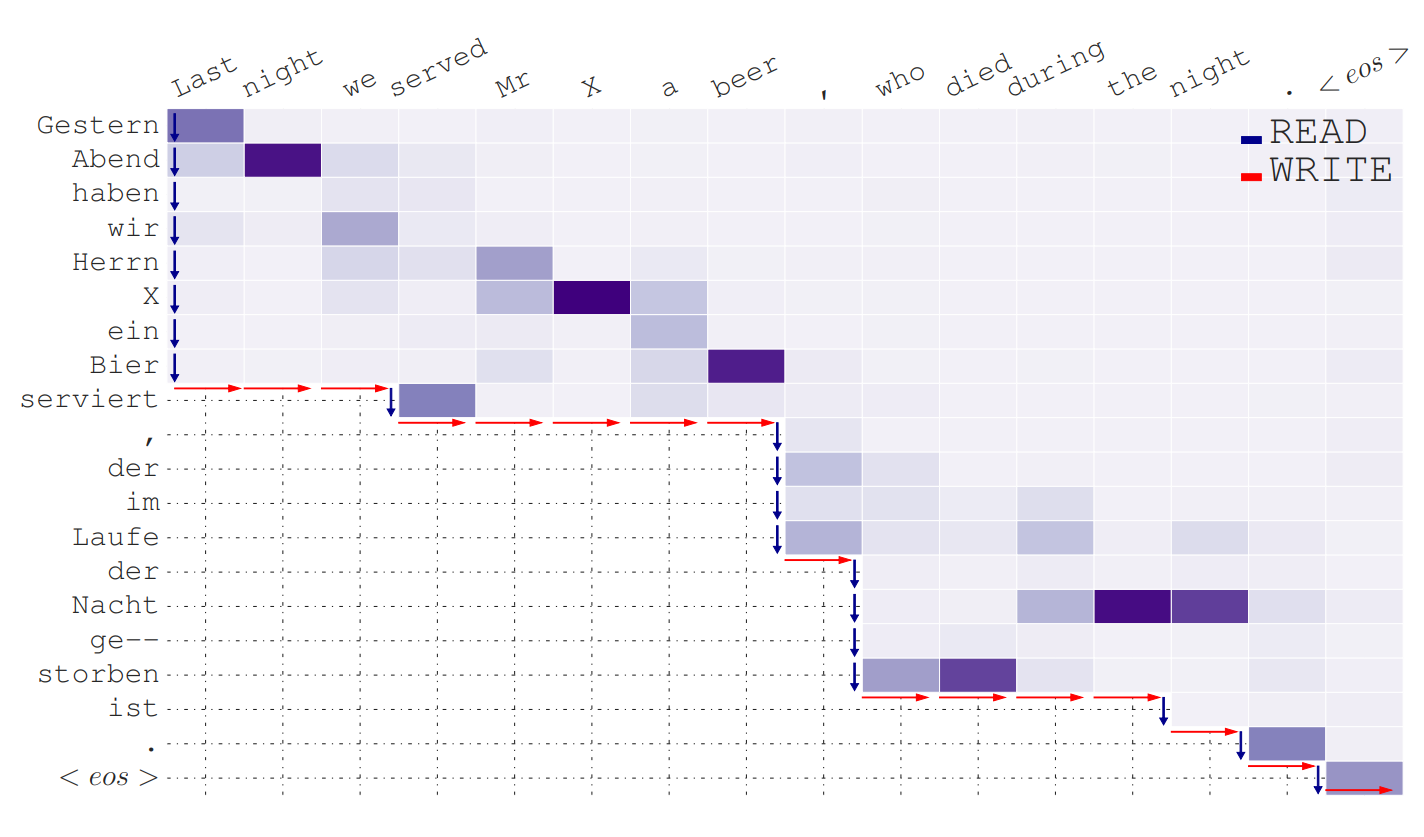
-
Learning to translate in real-time with neural machine translation
, Graham Neubig, Kyunghyun Cho, Victor OK Li
EACL 2017
BIB ABSTRACT
Translating in real-time, a.k.a. simultaneous translation, outputs translation words before the input sentence ends, which is a challenging problem for conventional machine translation methods. We propose a neural machine translation (NMT) framework for simultaneous translation in which an agent learns to make decisions on when to translate from the interaction with a pre-trained NMT environment. To trade off quality and delay, we extensively explore various targets for delay and design a method for beam-search applicable in the simultaneous MT setting. Experiments against state-of-the-art baselines on two language pairs demonstrate the efficacy of the proposed framework both quantitatively and qualitatively.
-
-
Trainable greedy decoding for neural machine translation
, Kyunghyun Cho, Victor OK Li
EMNLP 2017
BIB ABSTRACT
Recent research in neural machine translation has largely focused on two aspects; neural network architectures and end-to-end learning algorithms. The problem of decoding, however, has received relatively little attention from the research community. In this paper, we solely focus on the problem of decoding given a trained neural machine translation model. Instead of trying to build a new decoding algorithm for any specific decoding objective, we propose the idea of trainable decoding algorithm in which we train a decoding algorithm to find a translation that maximizes an arbitrary decoding objective. More specifically, we design an actor that observes and manipulates the hidden state of the neural machine translation decoder and propose to train it using a variant of deterministic policy gradient. We extensively evaluate the proposed algorithm using four language pairs and two decoding objectives and show that we can indeed train a trainable greedy decoder that generates a better translation (in terms of a target decoding objective) with minimal computational overhead.
2016
-
-
Incorporating copying mechanism in sequence-to-sequence learning
, Zhengdong Lu, Hang Li, Victor OK Li
ACL 2016
BIB ABSTRACT
We address an important problem in sequence-to-sequence (Seq2Seq) learning referred to as copying, in which certain segments in the input sequence are selectively replicated in the output sequence. A similar phenomenon is observable in human language communication. For example, humans tend to repeat entity names or even long phrases in conversation. The challenge with regard to copying in Seq2Seq is that new machinery is needed to decide when to perform the operation. In this paper, we incorporate copying into neural network-based Seq2Seq learning and propose a new model called CopyNet with encoder-decoder structure. CopyNet can nicely integrate the regular way of word generation in the decoder with the new copying mechanism which can choose sub-sequences in the input sequence and put them at proper places in the output sequence. Our empirical study on both synthetic data sets and real world data sets demonstrates the efficacy of CopyNet. For example, CopyNet can outperform regular RNN-based model with remarkable margins on text summarization tasks.